第一章:用函数构筑抽象
1.1 开始
计算机科学是极为广泛的科学。涉及的领域有全球的分布式系统,人工智能,机器人,图形学,安全,科学计算,计算机体系结构以及每年发掘的大量新兴的子领域对新技术的相关拓展。计算机科学的快速发展使得人类生活中的各个方面都收到影响。商业,通讯,科学,艺术,休闲,以及政治都在计算机领域被重新发明了。
只有计算机科学能够有这么高的生产率,因为这个学科是建立在一套优雅以及强大的基本思想上的。所有的计算都开始于表达信息,制定处理逻辑,以及设计抽象来管理复杂的逻辑。要掌握这些原理要求我们明白恰恰就是计算机是如何翻译计算机程序以及完成计算过程。
这些基本思想长期用SICP(Structure and Interpretation of Computer Programs)这本Harold Abelson以及Gerald Jay Sussman和Julie Sussman所写的教科书来教授,本书大量借用了这本教科书,原书作者允许我们在共享创作的许可协议下进行改编以及重用。这些笔记遵循知识共享署名非商业性类似共享许可证第三版
第一到三节讲的都是python的基本组成要素:
- 1.1 安装开发环境
- 1.2 编程要素,表达式、库的引入等
- 1.3 定义函数
因此,在1.4节,设计函数这里开始翻译,用于自己边翻译边理解
1.4设计函数
函数是所有程序语言无论其大小的必要组成部分,并作为我们的主要媒介在程序设计语言中表达计算过程。至今为止,我们已经讨论了函数的形式属性以及它们是如何应用的。现在我们将标题转向如何写一个好的函数。基本地,一个好的程序的质量全在于加强函数是抽象这个概念。
- 每一个程序都应该只有负责一个工作,这个工作有一个可识别的短名称以及可以用单行文字来进行表征。一个按顺序执行多项工作的函数应该被拆分到多个函数里面去。
- “不要重复你自己”是软件工程的中心宗旨。简称DRY原则,说的是多个代码片段不应该描述冗余的代码逻辑。相反,逻辑应该只实现一次,给出一个名称,并被多次调用。如果你发现自己复制并粘贴一个代码块,你可能找到了一个进行函数抽象的契机。
- 函数的定义应该具有一般性。平方这个方法恰恰不在Python函数库中,因为这是pow函数(可以将数字提升为任意次幂的函数)的特殊形式。
这些指南提升了代码的可读性,减少错误的数量,通常减少代码编写的总量。分解复杂任务到简洁的函数中是一项需要经验才能掌握的技能。幸运的是,Python提供了几样特性来支持你的努力。
1.4.1 文档
一个函数定义通常会在函数内包含文档定义,叫做docstring,必须要有与函数体一样的缩进。Docstrings通常是用三重引号来包含内容,第一行是用于描述函数的作用。接下来的行用于描述参数以及阐明函数的行为:
>>> def pressure(v, t, n):
"""Compute the pressure in pascals of an ideal gas.
Applies the ideal gas law: http://en.wikipedia.org/wiki/Ideal_gas_law
v -- volume of gas, in cubic meters
t -- absolute temperature in degrees kelvin
n -- particles of gas
"""
k = 1.38e-23 # Boltzmann's constant
return n * k * t / v
当你用一个名字作为参数来调用help函数时,你会看到它的docstring(点击q来退出Python帮助)
help(pressure)
当编写Python程序的时候,除了最简单的函数外,都要包含有docstring。要记住,代码只是编写一次,但是常被多次阅读。Python的文档有包含docstring的指南用于在不同项目之间保持一致性。
注释 。Python中的注释能够附加到任意行的结尾上,跟在#符号的后面。例如,上面的k的评论是用于描述玻尔兹曼常数。这些评论是不会出现在Python的help函数中的,同时也会被解释器忽略掉。它们只为了人而存在。
1.4.2
定义一般函数的结果是会引入额外的参数。一个函数如果有很多个参数的话在调用时会很尴尬而且也很难阅读。
在Python,我们能够为函数的参数提供默认的值。当调用函数时,具有默认值的参数是可选的。如果(调用函数时)没有被提供,参数的默认值会绑定到形式参数的名字上。例如,如果一个应用通常都是计算一摩尔的粒子的压力,这个值可以作为默认值来提供:
>>> def pressure(v, t, n=6.022e23):
"""Compute the pressure in pascals of an ideal gas.
v -- volume of gas, in cubic meters
t -- absolute temperature in degrees kelvin
n -- particles of gas (default: one mole)
"""
k = 1.38e-23 # Boltzmann's constant
return n * k * t / v
在这个例子中=符号意味着两种不同的东西,取决于使用它的上下文。在def声明语句头,=号并不执行分配而是表示pressure被调用时当做一个默认的值来用。相比之下,函数体中的k的分配声明将名字k与玻尔兹曼常数的近似值进行绑定。
>>> pressure(1, 273.15)
2269.974834
>>> pressure(1, 273.15, 3 * 6.022e23)
6809.924502
pressure函数定义为需要三个参数,但在上面第一个调用等式中只提供了两个参数值。在这种情况下,值n取自def声明的默认值。如果第三个参数被提供,默认值就会被忽略。
作为指导,大多数在函数体中用到的数据的值都应该表示为命名参数的默认值,使得它们易于被检查同时能被函数的调用者改变。一些永远不会改变的值,例如基本常数k,可以绑定到函数体或者全局内。
1.5 控制流
第五节用于描述控制流,if-elif-else以及一些测试相关的知识,属于基础知识,不翻译。
1.6 高阶函数
我们已经知道函数是一种抽象方法,用于描述与它们的参数的特定值无关的复合操作。也就是说,像square函数:
|
|
我们并没有讨论某个特定值的平方,而是讨论关于获得所有数字的平方的方法。当然,我们可以不去定义这样的函数,而是总写下这样的表达式:
|
|
并且从不明确提及square。这种做法对于简单的计算如square是足够了,但是对于更加复杂的例子像abs或者fib等要继续保持这样的做法就会变得很困难。一般来说,缺乏函数定义通常会使我们处于不利的地位,迫使我们总是在特定层级即语言的原语(在这个例子中是乘法)上工作,而不是在更高的层次上进行操作。即使我们的程序能够计算平方,但是我们的语言却缺乏表达平方概念的能力。
我们对于强大编程语言的其中一个需求是它提供的通过为常见模式分配名称构建抽象然后直接通过调用名称来执行工作的能力。就像我们接下来看到的例子,这是一个在代码中重复的常见模式,但是是与许多不同的函数一起使用。这种模式也可以通过命名来进行抽象化。
要将某些一般模式作为命名概念,我们需要构造函数让它能够接受其他函数作为其参数或者将函数作为其返回值。能够操纵函数的函数被称为高阶函数。本节将会展示高阶函数是如何能够作为强大的抽象机器从而大大增强我们的语言的表达能力的。
1.6.1 函数作为参数
研究一下接下来的三个都是用来计算总数的函数。第一个,sum_naturals,计算n个自然数的和
|
|
第二个,sum_cubes,计算n个自然数的平方和。
|
|
第三个,pi_sum,计算一系列项的总和
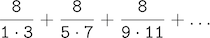
其非常缓慢地收敛到pi
|
|
这三个函数很显然使用了一种相同的底层模式,它们的大部分都是相同的,只有函数名以及函数中计算要累加的项的k的用法不同。我们可以通过在相同的模板中填充槽来生成每一个函数。
def <name>(n):
total, k = 0, 1
while k <= n:
total, k = total + <term>(k), k + 1
return total
这是这种共同模式存在的强有力的证据,等待着将有用的抽象带到表面上来。这些函数每一个都是求和术语,作为一个程序设计师,我们都希望我们的语言足够强大以至于我们能够能够编写函数来表达求和的概念,而不是对特定的值进行求和。在Python中我们可以轻易地将上面展示的模板中的槽替换成形式参数:
在下面的例子中,summation需要两个参数,上限n以及用来计算第k次值的函数term。我们能像使用其他函数一样来使用summation函数,它简洁地表现了求和(概念)。用点时间来一步步执行这个例子,注意下cube是如何绑定到局部命名term上的并保证结果111 + 222 + 333 = 36被正确计算的。在这个例子中,不需要的帧会被移除以用于节省空间。
使用一个可识别的函数来返回其参数,我们也能够用完全相同的summation函数来计算自然数的和。
|
|
这个summation函数也能够直接调用,而不用对特定序列来定义另一个函数
|
|
我们可以通过定义一个pi_term函数来计算每一次的值从而用我们的summation抽象函数来定义一个pi_sum,我们输入参数1e6,是1*10^6 = 1000000的简写,来生成pi的近似值。
|
|
1.6.2 作为一般方法的函数
我们采用用户定义函数作为抽象机制对数值运算进行抽象以让它们独立于特定的数。使用高阶函数,我们开始见识到更多抽象的力量:一些表达一般计算方法的函数,独立于它们调用的函数。
尽管这个概念拓展于什么是函数的定义,我们的环境模型评估一个调用表达式是如何无改变地优雅地拓展到高阶函数的。当用户定义函数应用于某些参数中时,形式参数跟这些参数(可能是函数)的值在一个新的局部帧内绑定到一起。
思考一下接下来的例子,一个应用迭代改进实现的用于计算黄金比率的通用方法。黄金比率,通常又叫做“phi”,是一个自然界、艺术、建筑学中经常出现的接近1.6的数字。
一个迭代优化算法开始于一个猜测的方程的解。它反复地应用一个更新函数来改进这个猜测的值,然后用一个接近的值来比较检查猜测值是否足够接近被认为是正确的值。
|
|
这个改进函数是一个重复细化的一般表达式,它没有指定问题应该怎么解决,这些细节都通过传入参数来留给update函数以及close函数来解决。
而总所周知的黄金比例属性是能够通过反复叠加一个任何正数加上1后的倒数来计算,而这个黄金比例属性是一个小于它平方的数字。我们可以将这些属性表达为一个用于改进的函数。
|
|
上面,我们引进了approx_eq函数调用,这函数意味着如果它的参数相互间足够约等于彼此就要返回True值。为了实现approx_eq函数,我们比较两个数之间的最小公差的绝对值。
|
|
用golden_update函数以及square_close_to_successor函数作为参数来调用improve函数将能够计算一个有限近似的黄金比率。
|
|
通过跟踪运算的每一步,我们能够看到这些结果是如何被计算出来的。首先,一个improve函数的局部环境被构造起来,并为update,close以及guess这三个参数绑定值。在improve函数体中,名为close的对象绑定了square_close_to_successor函数,用于被初始值guess来调用。继续跟踪接下来的几步来看计算黄金比率的演化计算过程。
这个例子演示了两个计算机科学上的大概念。第一,命名以及函数允许我们从大量的复杂性中进行抽象。虽然每一个函数的定义是微不足道的,但是我们评估程序的运行过程却是相当复杂的。第二,这是唯一的事实,我们有用于python语言的极其一般的计算步骤,就是一个小的组件能够组合成一个复杂的过程。明白程序的这个解析过程允许我们验证以及检查我们创建的过程。
像之前一样,我们新的一般函数improve需要一个测试来验证它的准确性。黄金比率能够提供这样的测试,因为它通常是具有一个精确的闭式解决方案的,可用于与迭代值进行比较。
|
|
对于这个测试,没有反馈消息就证明是好的:improve_test在它的assert声明执行之后返回一个None值。
1.6.3 定义函数 III:嵌套定义
上面的例子演示了将函数作为参数传递而显著地增强了我们的程序语言的表达力的能力。每一个一般的概念或者方程都映射到它的一个简短的函数上。这个方法的一个负面后果是全局环境会被命名以及那些唯一的小函数弄得十分凌乱。另一个问题是我们受特定函数签名的约束:update函数作为improve函数的参数只能传入一个形式参数。嵌套函数定义解决了这些问题,但是需要我们丰富我们的环境模型。
让我们来考虑新的问题:计算一个数的平方根。在编程语言中,“square root”通常缩写为sqrt。重复应用下面的收敛函数来更新a的平方根:
|
|
这个需要更新两个参数的函数跟improve函数(需要两个参数,而不是一个)是不兼容的,同时它只能对一个参数进行更新,然而我们真正在意的是通过迭代更新来获得平方根。解决所有问题的办法是将函数的定义放到另一个函数定义的函数体内。
|
|
就像本地赋值,本地的def语句只对当前的本地环境有影响。这些函数只适用于sqrt函数运行的范围内。跟我们求值步骤一样,这些本地的def语句直到sqrt函数被调用前都不会运行。
词汇范围。本地定义的函数还可以在定义它们的作用域中访问命名绑定。在这个例子中,sqrt_update函数引用名称a,而a是封闭函数sqrt的一个形参。这种在嵌套函数之间分享命名的规则叫做词汇范围。关键的是,内部函数能够访问它们定义范围(而不是调用范围)环境内的名称。
我们需要对我们的环境模型进行两个拓展从而让它们支持词汇范围。
- 每一个用户定义的函数都有一个父级环境:就是定义它时所处的环境。
- 当一个用户定义函数被调用时,它的本地域拓展自它的父级环境。
上一个sqrt函数,所有的函数都定义在全局环境,所以它们都有相同的父级环境:全局环境。相比之下,当Python运行sqrt的两个子句时,它创建了与本地环境关联的函数。在调用中
|
|
环境首先为sqrt添加局部帧以及运行sqrt_update以及sqrt_close的def声明。
每一个函数值都有一个新的注解就是从现在起我们会携带父级的环境图。函数值的父级是函数定义时的第一个环境作用域。没有父级注解的函数定义在全局环境。当一个用户定义函数被调用时,创建的帧拥有与函数一样的相同父级。
随后,名为sqrt_update的新定义的函数解决了那个只能接受一个参数的improve函数的问题。在improve函数的体内,我们必须应用x为1的初始猜测值到我们的update函数(绑定到sqrt_update函数)上。这个最后的应用为sqrt_update创建了一个一开始只有一个x以及一个绑定了a的父级环境sqrt的本地帧的环境。
这些求值步骤最关键部分是将sqrt_update的父代传递到通过调用sqrt_update创建的帧中,这个帧也用[parent=f1]来注释。
扩展环境。一个环境可以认为是任意长度的帧组成的一条总是包含全局帧的长链。如前面的sqrt例子所示,环境最多只有两个帧:一个本地帧,以及一个全局帧。通过调用一个会在内部用def声明来定义其他函数的函数,我们可以创建一个长链。调用sqrt_update的环境有三个帧组成:本地的sqrt_update帧,定义sqrt_update函数的sqrt帧(标记为f1),以及全局帧。
sqrt_update函数内部的返回表达式能够通过这条帧链解析a的值。查找名称会找到当前环境中绑定到该名称的第一个值。Python首先在sqrt_update帧中进行查找–没有找到a的存在。Python接下来到父级帧中查找,即f1,然后找到绑定了256的a。
因此,我们认识到Python中的两个词汇范围的关键优点。
- 本地函数的命名不会干扰到外部定义的相同名称的函数,因为本地函数名称会绑定到它定义的当前的本地环境中,而不是全局环境。
- 一个本地函数能够访问封闭函数的内部环境,因为本地函数的函数体求值环境是在它被定义的求值环境中拓展出来的。
sqrt_update函数携带了一些数据:在定义a的范围中的引用值。因为它们通过这种方式“包围”信息,本地定义函数通常叫做闭包。
1.6.4 函数作为返回值
我们能够通过在程序中创建一个返回值是自己内部创建的函数的函数来获得更多的表现力。具有词法作用域的编程语言的一个很重要的特性是本地定义的函数当它们(作为返回值)被返回的时候能够维持它们的父级环境。接下来的例子说明了这个特性的效用。
一旦定义了很多的简单函数,函数组成了一种自然的方法组合包含在我们的编程语言里面。也就是说,给定两个函数f(x)以及g(x),我们可能希望定义h(x)=f(g(x))。我们能够定义函数组合来使用我们现有的工具:
|
|
这个例子的环境图示显示了名称f以及g是如何正确解析的,即使存在名称冲突。
在compose1中的1表示的意味是组合的函数全都只接受一个参数。这个命名约定并不是解析器强制要求的,这个1只是函数名的一部分而已。
到现在,我们开始注意到我们努力定义精确环境模型的计算的效益。这种方式无需修改我们的环境模型来解释我们返回函数的能力。
1.6.5 例子:牛顿法
这个拓展的例子展示了函数返回值以及本地定义如何能够一起工作来简洁地表达一般思路的。我们会实现一个广泛用于机器学习,科学计算,硬件设计以及优化的算法。
牛顿法是一个经典的用于找寻返回值为0的数学函数的参数的迭代方法。这些值被称为函数的零点。找寻函数零点相当于解决一些其他有趣的问题,比如计算平方根。
在我们继续之前先来激励一下自己:我们很容易认同这样的一个事实就是我们知道如何计算平方根。不仅仅是Python、甚至是你的电话,浏览器,或者袖珍计算器也能够为你做到这一点。然而,学习计算机科学的其中一部分就是要明白像这样的数量是如何计算出来的,以及这里所呈现超越那些Python内置方法能够计算一大类方程的一般方法。
牛顿法是一个迭代改进算法:它对任何可区分的函数的零点的猜测值进行改进,也就意味着它能够通过利用直线来趋近任何点。牛顿法遵循这些趋近直线来找到函数的零点。
想象一条直线穿过一个点(x, f(x)),且跟在这点上的曲线函数f(x)具有相同的坡度。这样的先叫做切线,它的坡度就叫做函数f在x上的导数。
这条直线的坡度就是函数值跟随函数输入参数变化的比率。因此,将x转换为f(x)除以坡度会得到该切线触及0的参数值。
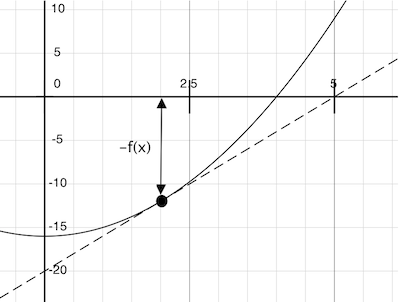
newton_update表示对于函数f以及它的导数df,该切线为0的计算过程。
|
|
最终,我们能够用我们的newton_update函数、改进算法improve以及比较看f(x)是否接近0来定义find_root函数。
|
|
计算根。用牛顿法我们能够计算任意度n的根。a的n度根是指像x * x * x … x = a中x的重复次数n。例如
- 64的平方(二次)根是8,因为8 * 8 = 64。
- 64的立方(三次)跟是4,因为 4 * 4 * 4 = 64。
- 64的六次方根是2,因为2 * 2 * 2 * 2 * 2 * 2 = 64。
通过接下来的观察我们可以用牛顿法来计算根:
- 64的平方根(√64)就是x的值为x * x - 64 = 0
- 更普遍地,a的n度根就是x的值为 x * x * x … n个x - a = 0
如果我们能够找到最后一个问题的零点,我们就可以计算n度根。通过绘出n等于2、3以及6,a等于64的曲线,我们能够将关系可视化。
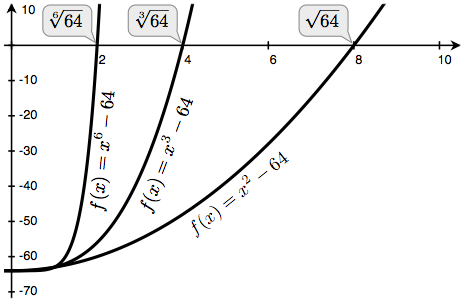
我们通过定义f以及它的导数df首次实现square_root函数。我们用微积分中的定理:f(x) = x * x - a的导数就是线性函数df(x) = 2x。
|
|
归纳来说,任意度n的根我们通过计算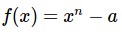 以及它的导数
以及它的导数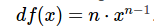 可得
可得
|
|
所有的这些计算中的近似误差可以通过修改approx_eq函数中的tolerance(公差)来减少到一个更小的值。
当你练习牛顿法的时候,需要留心它并不总是收敛。improve函数的初始猜测需要充分地接近到零点,且必须满足函数的各种条件。尽管有这些缺点,牛顿法还是一个很强大的求解可微分方程的一般计算方法。对数和大整数除法在现代计算机中采用该技术的变体是一种非常快的算法
1.6.6 柯里化
我们可以使用高阶函数来改造一个携带多个参数的函数为一个函数链,且函数链中的每一个函数都接受一个参数。更特别地,给定一个函数f(x, y),我们可以定义一个函数g让g(x)(y)等于f(x, y)。这里,g是一个更高阶的函数接受一个x参数然后返回另一个函数来接受参数y。这种转型称为柯里化。
举个例子,我们可以定义一个柯里化版本的pow函数:
|
|
一些编程语言,如Haskell,只允许函数有一个参数,因此程序员必须要柯里化所有的多参数程序。在更一般的语言中,如Python,当我们需要一个只接受一个参数的函数时柯里化就十分有用了。例如,映射模式可以将一系列的值应用到接受单个参数的函数中。在随后的章节中我们会看到更多映射模式的一般例子,但是现在,我们可以在函数中实现这种模式;
|
|
我们可以使用map_to_range以及curried_pow来计算前十个数的平方,而不是特地写一个函数来做这些操作:
|
|
我们可以类似地使用相同的两个函数来计算其他数字的幂。柯里化允许我们这样做而不需要为每个数编写特定的函数来计算我们想要的幂。
在上面的例子中,我们手动执行柯里化来将pow函数转化为curried_pow函数。作为替代,我们可以定义函数来自动实现柯里化,以及逆柯里化的实现:
|
|
curry2函数接受一个需要两个参数的函数f然后返回一个需要一个参数函数g。当用一个参数x调用g时,它返回一个需要单个参数的函数h。当用一个y调用h时,它调用f(x, y)。因此,curry2(f)(x)(y)就相当与f(x, y)。uncurry2函数逆转柯里化变换,因此uncurry2(curry2(f))就等于f。
|
|
1.6.7 Lambda表达式
至今为止,每一次我们想要定义一个新的函数,我们都需要给它一个名字。但是对其他类型的表达式,我们无需给中间结果给关联一个名称。也就是说,我们能够计算a*b+c*d而不需要命名子表达式a*b或者c*d,或者整个表达式。在Python里面,我们可以用lambda表达式来计算未命名的函数从而动态地得到一个函数值。一个lambda表达式计算的函数在函数体内有单独的一个返回表达式。赋值语句以及控制语句是不被允许使用的。
|
|
我们能够通过构造一个相应的英文句子来明白lambda表达式的构造:
lambda x : f(g(x))
"A function that takes x and returns f(g(x))
lambda表达式的结果叫做lambda函数。它没有固有的名称(因此Python打印<lambda>作为它的名称),但是除此之外它的行为就像其他函数一样。
|
|
在一个环境关系图里面,lambda表达式的结果就是一个函数,名为希腊文的 λ (lambda)。我们撰写的例子能够相当紧凑地表达lambda表达式。
一些程序员发现,使用来自于lambda表达式的无命名的函数会更加的短也更加直接。然而,尽管它们很简洁,复合的lambda表达式却是臭名昭著且难以辨认的。下面的定义是正确的,但是很多程序员在快速明白它的意图上会遇到困难。
|
|
一般来说,Python风格更偏向于显式的def声明而不是lambda表达式,但是允许它们存在是为了防止需要一些简单的函数作为参数或者返回值。
这些风格规则仅仅只是指导性的,你可以以任何你想要的方式来编程。然而,当你编程的时候,想一下那些将来有一天会读你的程序的读者。当你可以让你的程序更容易明白,你就是在帮这些人一个忙。
lambda术语是一个历史事故,来源于书面数学符号以及早期类型系统的约束的不兼容而导致的。
It may seem perverse to use lambda to introduce a procedure/function. The notation goes back to Alonzo Church, who in the 1930’s started with a “hat” symbol; he wrote the square function as “ŷ . y × y”. But frustrated typographers moved the hat to the left of the parameter and changed it to a capital lambda: “Λy . y × y”; from there the capital lambda was changed to lowercase, and now we see “λy . y × y” in math books and (lambda (y) (* y y)) in Lisp.
—Peter Norvig (norvig.com/lispy2.html)
尽管有这个不同寻常的词源,lambda表达式以及相应的函数应用的形式语言,lambda演算,是基本的计算机科学概念并广泛在Python编程社区中共享。当我们在第三章学习设计一个编译器时,我们会再次回顾这一个主题。
1.6.8 抽象以及第一类函数
我们这一节开始观察用户定义函数这个关键的抽象机制,因为它们允许我们在我们的编程语言中用显式的元素来表达一般的计算方法。现在,我们已经见识过高阶函数是如何允许我们来操作这些一般方法以创建进一步的抽象的。
作为一个程序员,我们应该警惕并识别定义我们程序的底层抽象的机会,建立在它们之上,然后归纳它们来构建更加强大的抽象。这并不是说应该总是以最抽象的方式来编写程序;高级的程序员知道如何选择适合他们当前任务的抽象等级。但能够从抽象的角度来想这些问题是很重要的,以便我们可以准备将它们应用到新的上下文当中去。高级函数的意义在于它们允许我们来表示这些抽象概念,特别是作为我们编程语言里的一个元素来使用,以便它们能够处理像出来其他计算元素一样来进行处理。
一般来说,编程语言会对可以操纵的计算元素的方式施加限制。进行最小的限制的元素被称为第一类元素。第一类元素的“权利与特权”如下:
- 它们可能会绑定到一个名称上
- 它们可能会作为函数的参数来传递
- 它们可能作为函数的结果来返回
- 它们可能包括在数据结构当中
Python授予函数充分的第一类元素的所有状态,得到的结果就是巨大的表现力。
1.6.9 函数装饰器
Python提供特殊的语法来以应用高阶函数作为def声明的一部分来使用,这叫做装饰器。可能最常见的例子就是追踪函数了:
|
|
在这个例子中,已经定义了一个高阶函数trace,它返回一个函数,这个函数在对其参数进行调用之前会先执行print语句来输出参数值。triple的def声明有一个备注:@trace,这个备注会影响def的执行规则。一般来说,函数triple已经创建好了,然而,名称triple并不是绑定到这个函数上,而是triple这个名称被绑定到trace调用时返回的新定义的triple函数上。在代码中,这个装饰器相当于:
|
|
在与本文相关的项目中,装饰器用于跟踪,以及从命令行运行程序时选择要调用的函数。
给专家的额外资料。这个装饰器的符号@通常通常在后面会跟一个表达式。这个跟在后面的表达式已经先被运行了,(就像上面运行的名为trace的表达式),第二个def表达式以及最终运行装饰器表达式的结果会应用到最新定义的函数上,而最终结果会绑定到def声明的名称上。一个Ariel Ortiz写的剪短的装饰器教程给有兴趣的同学。
1.7 递归函数
一个函数如果它自己的函数体调用函数本身就称作递归函数,不管是直接的或者间接的。也就是说递归函数函数体的执行过程中可能会反过来需要再次调用这个函数。在Python中的递归函数并不需要用到特殊的语法,但它们确实需要做出一些努力才能明白并创建。
我们从一个示例问题来开始:编写一个函数用来计算一个自然数的所有位数的数字之和。当设计递归函数时,我们需要寻找将遇到的问题分解成更简单的问题的方法。在这个例子中,操作符号$以及//可以用来将数字分成两部分:它最后的一个数以及除了最后一个数的所有数字。
|
|
数字18117的各位数之和是1+8+1+1+7 = 18。正如我们可以将数字分解,我们可以将数字分解成最后的一个数字7,以及除最后的一个数字以外的所有数字,1+8+1+1 = 11。这种拆分提供了一种算法来一个数n的所有位数数字之和,将它的最后一位数n % 10加上剩余的数字n // 10。这是一个特殊的例子,如果一个数字只有一个数,那么这个数各位数字的和就是它自己。这个算法可以实现为一个递归函数。
|
|
sum_digits的定义是完备且正确的,即使这个sum_digits函数在它自己的函数体内被调用。计算位数之和的问题被分解成两步:计算除了最后一个数字以外的各位数字之和,然后加上最后一位数字。这些步骤都比原问题更加简单。这是一个递归函数,因为第一步跟原问题的第一步一样。也就是说,sum_digits就是我们要实现sum_digits所需要的函数:
|
|
我们可以通过环境计算模型来恰当地理解递归函数是怎么成功运行的。无需任何新的规则。
当执行def声明,名称sum_digits绑定到了新的函数当中,但是函数体还没有执行。因此,sum_digits的循环特性还不是一个问题。然后,用738sum_digits来调用sum_digits:
- 一个n被绑定为738的
sum_digits函数的本地帧被创建了,然后sum_digits的函数体开始在这个本地帧的环境中进行调用。 - 由于738不小于10,因此第四行的赋值语句被执行,将738分解成73和8。
- 在接下来的返回语句中,
sum_digits被当前环境中的all_but_last值73调用 - 另一个
sum_digits的本地帧被创建,这一次n绑定的是73,sum_digits的函数体再一次执行在这个帧中的新环境中。 - 由于73并不小于10,73分解成7和3,然后
sum_digits用这个帧中的all_bug_last的值7来进行调用。 - 第三个n绑定为7的
sum_digits的本地帧被创建 - 开始于这个环境的帧,
n < 10的是正确的,因此,7被返回。 - 在第二个本地帧里面,这个返回值7与3这个
last值进行相加,然后返回10。 - 在第一个本地帧里面,返回值10与8这个
last值相加,然后返回18
这个递归函数的应用是正确的,尽管它具有环形调用的特征,因为它的两次调用中每一次都用不同的参数值来进行调用。此外,第二次调用是比第一次更简单的数字求和问题。从生成的调用sum_digits(18117)的环境图例来看,每一个连续的调用sum_digits都会得到比前一个更小的参数值,直到达到最终的单位数的输入。
这个例子也说明了一个具有简单函数体的函数是如何通过递归来解决复杂问题的。
1.7.1 剖析递归函数
在许多递归函数的函数体内都能够找到一种常见的模式。函数体开始于一个基础情况,一个条件语句定义了函数对于输入的最简单的处理行为。如果是sum_digits,基础情况就是任何单个的数字参数,我们简单地返回这个参数,一些递归函数会有多个基本情况
基础情况之后会跟随一个或者多个递归调用。递归调用总是会具有某些特性:它们会简化原问题。递归函数通过逐步简化问题来表达计算行为。例如,求数字7的和比求数字73的和要简单,而后者又比求数字738的和要简单,随后的每一次调用都比前前一次需要做更少的工作,递归函数通常用不同的方式来解决我们之前用迭代方式来解决的问题。考虑下用函数fact来计算n的阶乘,如例子fact(4)的计算为4! = 4 * 3 * 2 * 1 = 24。
一个正常的实现是用while语句累计直到n的每一个正整数的总的乘积。
|
|
另一方面,递归实现阶乘可以表达fact(n)为fact(n-1),一个更简单的问题。递归的基础情况是问题的最简单形式:fact(1)是1。
这两个递归函数在概念上是不同的。迭代函数从最简单的基础情况1开始依次乘上每一个数来构造结果。另一方面,递归函数直接从最后一个数n以及更简单的问题fact(n-1)的结果来构造结果。
随着递归函数连续应用fact函数来逐步展开问题为越来越简单的实例,结果最终从最简单的情况开始构建。递归结束于传入参数1到fact函数中,每一次调用的结果都依赖于下一次调用,直到达到基础情况。
这个递归函数的正确性很容易从阶乘的数学函数的标准定义上来进行验证的:
当我们能够用我们的计算模型进行递归展开的时候,这通常就能够很清晰地将递归调用作为函数抽象来思考了。也就是说,我们不应该关心fact(n-1)是如何在fact的函数体内实现的;我们应该相信它能够计算n-1的阶乘,将递归调用当做函数抽象来对待已经可以认为是一种_递归信念的飞跃_。我们用一个函数本身来定义了一个函数,但在验证它的正确性时,仅仅需要相信最简单的情况下会正确工作。在这个例子中,我们相信fact(n-1)会正确计算(n-1)!;如果这个假设是正确的我们只需检查n!的计算是正确的。通过这种方式,检查递归函数的正确性就是证明一种形式的归纳。
函数_fact_iter_以及_fact_函数也是不同的,因为前者必须添加两个名字,total以及k,这在递归函数的实现中是不必要的。一般来说,迭代函数,在计算的过程中必须维持一些计算过程中的本地变量。在迭代的任何一个点上,这些状态表示已完成工作的结果和剩余工作量。例如,当k是3以及总数是2时,这时还剩余两项需要处理,就是3和4。另一方面,_fact_的特征在于它的单个参数n。整个计算的状态包含在环境的结构中,也就是起到作用的total值,以及在不同的帧内绑定n到不同的值而不是明确的k的踪迹。
回调函数利用调用表达式来求值的规则为名称绑定一个值,通常避免在迭代期间正确地分配本地名称的烦扰。出于这个原因,递归函数能够更容易正确地定义。然而,学习识别递归函数演化的计算过程当然少不了实践。
1.7.2 相互递归
当一个递归过程分为两个相互调用彼此的函数时,这个函数就被叫做相互递归。举个例子,想象一下下面的非负整数的奇数和偶数的定义:
- 一个数是偶数如果它比一个奇数多一
- 一个数是奇数如果它比一个偶数多一
- 0是偶数
用这个定义,我们可以实现相互递归函数来确定一个数是奇数还是偶数:
相互递归函数能够通过打破两个函数之间的抽象边界来变成单递归函数。在这个例子中,is_odd的函数体能够合并到is_even中,确保将is_odd中的n改成n-1,来体现传入参数这个动作。
|
|
因此,相互递归并没有比简单递归有更多的神秘与强大,只不过它提供了一种在复杂的递归程序中维护抽象的机制而已。
1.7.3 在递归函数中打印
由递归函数演化的计算过程通常可以通过调用print来进行可视化。举个例子,我们会执行一个函数cascade来打印一个数的前面几个数,从最大到最小再到最大。
|
|
在这个递归函数中,最基础的情况是单一一个数字,直接打印。否则,递归函数在两个打印之间被调用。
基础情况在递归函数之前进行调用并不是硬性规定的。实际上,通过观察可知print(n)这个表达式在判断语句前后重复出现了,因此通过将打印语句提前可以让这个函数表达得更紧致。
|
|
举另外一个相互递归调用的例子,想象一下一个双人游戏,最开始在桌面上有n个鹅卵石。玩家轮流从桌面上拿走一个或者两个鹅卵石,最后一个移动鹅卵石的人就算作胜利。假设Alice和Bob玩这个游戏,每个人都用最简单的策略:
- Alice总是拿走一个鹅卵石
- 如果桌面上剩下双数个鹅卵石,Bob就拿走两个鹅卵石,否则就拿走一个
给定n个鹅卵石然后从Alice开始,那么谁会赢得游戏?
一个自然的分解这个问题的办法是将每一个策略封装到各自的函数中去。这允许我们改动一个策略而不影响另一个策略,在两者之间维护一个抽象屏障。为了实现这个游戏一轮又一轮的性质,这两个函数在每一轮最后的位置相互调用彼此。
|
|
在play_bob中,我们看到在一个函数体内可能会出现多个递归的调用。然而,在这个例子中,每一次调用play_bob最多只调用play_alice一次。在下一节中,我们会考虑一下当一个函数调用时直接调用多个递归会发生什么事。
1.7.4 树递归
另一个计算的一般模式称作树递归,也就是一个函数调用自己超过一次以上。举个例子,想象一下,计算一个斐波那契序列,每个数都是前两个数的和。
相对于我们之前的尝试,这个递归定义是十分吸引人的:它准确地反映了斐波那契数的定义。一个函数有多个递归调用被称为树递归,因为每一个调用都会分支出更多小的分支调用,而这些小分支又分支出更小的调用,就像是一棵树的分支一样从树干延伸,越来越小,却越来越多。
我们之前就已经能够定义不需要树递归的计算斐波那契数的方式。实际上,我们之前的尝试会更加的高效率,这是本文后面讨论的主题。接下来,我们考虑一个问题为什么树递归会比任何一个迭代替代方案都要简单得多。
1.7.5 例子:分割
正整数n的分割数,使用最大的尺寸的m,是一个数n可以表现最大为m以递增顺序表现的正整数部分的和。例如,使用4作为6的分割数的话,可以有9种情况。
- 6 = 2 + 4
- 6 = 1 + 1 + 4
- 6 = 3 + 3
- 6 = 1 + 2 + 3
- 6 = 1 + 1 + 1 + 3
- 6 = 2 + 2 + 2
- 6 = 1 + 1 + 2 + 2
- 6 = 1 + 1 + 1 + 1 + 2
- 6 = 1 + 1 + 1 + 1 + 1 + 1
我们会定义一个函数count_partitions(n, m),它会返回使用最大分割数m的n的分割数量,这个函数有个一个简单的树递归的实现形式,以下面的观察作为依据:
用m作为最大分割数的n的分割种类有:
- 使用最大为m的整数来划分n-m的方式的种类,加上
- 使用最大为m-1的整数来划分n的方式的种类
来看下为什么这是对的,观察可知所有的分割n的方式的数量能够分成两组:那些至少包括一个m的跟所有不包括m的。此外,第一组中的每个分割类型是n-m的分割,随后在末尾加上m。在上面的例子中,最先的两个分割包含4,其他的则不包含。
因此,我们可以通过使用两个更简单的问题递归地减少最大直到m的整数来分割n:(1) 分割更小的数n-m,以及 (2) 分割具有更小分量的整数直到m-1。
要完成函数实现,我们需要指定以下的基础情况:
- 分割0的方式只有一种:不包括任何部分
- 分割负数n的方式有0种。
- 分割任何大于0的n但是用小于等于0作为组成部分的分割方式只有0种。
|
|
我们可以认为树递归函数是在进行不同可能性的探索。在这个例子中,我们探索可以用作分割的m的大小的可能性以及不可用作分割的可能性。第一以及第二个递归调用对应这些可能性。
用非递归方式实现这个函数需要更多的投入,鼓励感兴趣的读者进行尝试。