第四章: 数据处理
4.1 介绍
现代计算机可以处理大量表示世界许多方面的数据. 从这些大数据集合, 我们可以以前所未有的方式学习到人类的相关行为: 语言是如何使用的, 拍摄什么照片, 讨论什么话题, 以及人们是如何跟他们周围的环境来接触的. 为了高效地处理大数据集合, 程序被组织成对有序的数据流进行操作的管道. 在本章, 我们会考虑一套的技术来处理并操纵有序数据流.
在第二章, 我们会引入序列接口, 通过内置的数据类型(如列表和范围)来在Python中实现. 在这章中, 我们将会拓展序列数据的概念, 包括不具边界甚至是无限大小的集合. 两个数学上的无限序列例子是正整数以及斐波那契数列. 具有无限长度的序列数据集合也出现在其他计算领域. 例如, 通过电话塔发送的电话序列, 由计算机用户进行的鼠标移动的序列, 以及飞机上传感器的加速度测量序列随着世界的发展而无限延伸.
4.2 隐含序列
一个序列可以无需对每个元素进行明确存储在计算机的存储器中而表示出来. 也就是说, 我们可以构造一个对象来提供访问某些顺序数据集的所有元素而不用提前计算所有这些元素并保存它们. 相反, 我们按需来计算元素.
这个想法的一个简单的例子出现在第二章介绍的range序列类型中. 一个range表示一个连续, 有界的整数序列. 然而, 序列的每个元素在这个情况下并不是明确存在于内存中的. 相反, 当range中的元素被请求时, 它会计算出这个元素. 因此, 我们可以表示非常大的整数而不用大块的内存. 只有range的终结点存储为range对象的一部分.
|
|
在这个例子中, 不是所有在999,990,000这个范围的整数在创建的时候都会被存储. 相反, 范围对象添加第一个元素10,000一直到到下标45,006,230来产出元素45,016,230. 一旦请求就会计算值而不是从一个已存在的表示来检索它们, 这是一个懒计算的例子. 在计算机科学, 懒计算描述任何延迟计算的程序, 直到需要该值为止.
一个迭代器是一个对象, 它提供对底层顺序数据集的顺序访问. 迭代器在很多程序中是内建对象, 包括Python. 迭代器的抽象具有两个部分, 一个在一个底层元素中检索下一个元素的机制以及一个发出已经到达序列的终点并没有更多元素的信号机制. 在具有内建对象系统的编程语言中, 这个抽象通常来说对应到特定的可以通过类来实现的接口. Python提供的迭代器接口描述会在下一节中描述.
迭代器的有用性源于一个事实即: 迭代器的底层数据序列可能不会在存储器中明确表示. 迭代器提供了一个机制来顺序考量一系列数据的值, 但同时所有的元素不需要存储在内存中. 相反, 当下一个元素被迭代器请求, 元素可以根据需要计算而不是从现有内存源中检索.
范围类可以对一个列表的元素进行懒计算因为所表示的序列是均匀的, 同时任何元素都容易从range的开始和结束的边界计算. 迭代器允许懒生成更广泛类型的底层顺序数据集, 因为它们不需要提供对任意元素的底层序列的访问. 相反, 迭代器只需要在每次请求一个元素时按顺序去计算该序列中的下一个元素. 虽然不像访问序列的任意元素一样灵活(称为随机访问), 顺序访问顺序数据序列通常来说足以用于数据处理应用.
4.2.1 Python迭代器
Python的迭代器接口是用一个叫做__next__的方法来定义的, 它会返回它所代表的一些底层序列数据的下一个元素. 响应调用__next__方法, 迭代器可以执行任意计算以便检索或者计算出下一个元素. 调用__next__会为迭代器带来突变型的改变: 它推进了迭代器的位置. 因此, 多次调用__next__会返回一个底层序列的序列元素. Python在调用__next__期间通过发出StopInteration异常的形式来表示一个底层序列已经到达尽头.
下面的LetterIter类迭代一个以某些字母开头的而不包括某些字母结束的底层序列. 实例属性next_letter保存下一个字母用来返回. __next__方法返回这个字母并使用它来计算新的next_letter.
|
|
使用这个类, 我们可以顺序地访问字母通过__next__方法或者内建的next函数, 这个函数会调用传入的参数上的__next__方法.
|
|
迭代器是可变的, 当它们演变事, 它们会跟踪某些底层序列值的位置. 当到达最后的值时, 迭代器就用完了. 一个LetterIter实例只可以被迭代一次. 在它的__next__()方法抛出StopIteration异常之后, 从这时起这个迭代器就会一直这样做. 通常, 一个迭代器是不可以重置的; 而是创建一个新实例来开始一个新的迭代.
迭代器也允许我们通过实现一个永远不会抛出StopIteration异常的__next__方法来表示一个无限序列. 例如, 下面的Positives类用来迭代无限的正整数序列. 在Python中内建的next方法会调用它参数上的__next__方法.
|
|
4.2.2 可迭代对象
如果一个对象在调用它的__iter__方法时返回一个迭代器那么这个对象是可迭代的. 可迭代值代表数据集, 并且它们提供可能产生多于一个迭代器的固定表示.
例如, 下面的Letters类的实例表示一个连续的字母序列. 每一次它的__iter__方法被调用, 一个新的LetterIter实例就被构造, 它允许顺序访问到序列的内容.
|
|
内建的iter函数调用传入的参数上的__iter__方法. 在下面的序列表达式中, 两个迭代器衍生自相同的可迭代的序列并独立地返回序列中的字母.
|
|
可迭代的Letters实例b_to_k以及LetterIter的迭代器实例first_iterator以及second_iterator与Letters实例的不同之处在于Letter实例不会更改, 而迭代器实例会随着每一次next调用(或者等效的__next__调用)之后改变. 迭代器通过顺序数据跟踪进度, 而可迭代表示数据本身.
在Python中的很多内建函数接受可迭代参数并返回一个迭代器. 例如, map函数, 接受一个函数以及一个可迭代的值. 它返回对可迭代参数的每个元素应用到传入函数后的返回结果组成的一个迭代器.
|
|
map函数是惰性函数, 调用它时并不会执行计算其元素结果所需的计算. 相反, 一个迭代器对象被创建后, 如果使用next函数查询则可以返回结果. 我们可以在下面的例子中观察到这个事实, 打印的操作被延迟到了对应元素被doubled迭代器请求才操作.
|
|
filter, zip以及reversed函数也是返回迭代器的.
4.2.3 声明
在Python中的for声明用于操作迭代器. 对象如果具有一个__iter__方法, 返回一个迭代器, 那么它是可以迭代的(一个接口). 可迭代对象可以是for声明头部的<expression>中的值:
|
|
为了执行for声明, Python执行头部<expression>, 这个expression必须返回一个迭代器值. 然后, 在该至上调用__iter__方法. 直到StopIteration异常被抛出, Python反复调用在这个迭代器上的__next__方法以及绑定结果到<name>在for声明中. 然后, 它执行<suite>.
|
|
在上面的例子中, counts列表从它的__iter__()方法中返回一个迭代器. for声明之后不断地调用这个迭代器的__next__()方法, 同时每次都将返回值分配到item上. 这个过程一直持续直到迭代器抛出StopIteration异常, for声明在这个点上结束执行.
随着我们对迭代器的了解, 我们可以以while, 赋值, 以及try声明, 实现执行for的规则.
|
|
上面, 通过调用counts迭代器的__iter__方法并将返回的值绑定到名称items上, 这样就可以依次查询每个元素. 处理StopIteration异常的处理机制什么都不会做, 但是这个处理机制提供了一个控制机制来跳出while循环.
在for循环中使用一个迭代器, 这个迭代器也必须具有一个__iter__方法. Python文档中的Iterator类型章节建议一个迭代器具有一个__iter__方法, 这个方法返回迭代器本身, 因此所有的迭代器都是可迭代的.
4.2.4 生成器以及yield声明
上面的Letters以及Positives对象需要我们去引入一个新的域self.current到我们的对象来跟踪序列进度. 使用如上面展现的这样简单的序列, 可以很容易完成. 然而对于复杂的序列, __next__方法就很难在计算中保持它的位置. 生成器允许我们利用Python解析器的功能去定义更复杂的迭代.
生成器就是通过一个特殊类型的函数返回一个迭代器对象的函数. 生成器函数有别于常规的函数的地方在于它们的函数体内不是包含return声明, 它们使用yield声明来返回序列的元素.
生成器并不使用对象的属性来追踪序列的步进过程. 相反, 它们控制生成器函数的执行过程, 每一次生成器的__next__方法被调用就会一直执行直到下一个yield声明被执行才停止. Letters迭代器可以使用生成器函数来实现得更加紧凑.
|
|
即使我们从来没有明确地定义__iter__或者__next__方法, yield声明指出我们正在声明一个生成器函数. 当函数被调用时, 生成器函数不是返回一个特定的产生的值, 而是一个生成器(它的类型是一个迭代器)它本身可以返回产生的值. 生成器对象具有__iter__以及__next__方法, 同时每一次调用__next__会继续从上一次生成器函数离开的地方继续执行生成器函数直到另一个yield声明被执行.
第一次调用__next__, 程序会执行来自letters_generator函数主体的语句, 直到它遇到yield声明. 然后, 它暂停并返回值给current. yield声明并不会销毁最新创建的环境, 它们将保留下来. 当__next__再次被调用, 执行过程恢复到它停止的地方, current的结果以及其他在这个letters_generator域之中绑定了的名称都会保留直到随后的__next__调用.
我们可以通过手动调用__next__()来遍历生成器:
|
|
生成器不会开始执行其生成函数的任何body语句, 直到__next__第一次被调用. 当生成器结束时会抛出StopIteration异常.
4.2.5 创建带有yield的可迭代对象
在Python, 迭代器只能单向通过底层迭代序列的元素. 在这之后, 迭代器在__next__再次被调用时会继续抛出StopIteration异常. 很多程序需要重复元素多次. 例如, 我们要迭代列表多次来枚举所有元素对.
|
|
序列本身并不是迭代器, 而是可迭代对象. 在Python中的可迭代接口由单个消息组成, __iter__, 它返回一个迭代器. 在Python中的内建序列类型在它们的__iter__方法被调用时返回新的迭代器的实例. 如果一个可迭代对象每次__iter__方法被调用时就返回一个新的实例, 那么它就可以迭代多次.
新的可迭代类可以通过实现可迭代接口来定义. 例如, 下面的_可迭代_LettersWithYield类每次在__iter__被调用时返回一个新的建立在字母上的迭代器.
|
|
__iter__方法是一个生成器函数; 它返回一个生成器对象这个生成器对象返回字母a到d然后就停止. 每次我们调用这个方法, 一个新的生成器会开始迭代一个新的序列数据.
|
|
4.2.6 流
流通常是隐含地表示序列数据的另一种方式. 流是一个懒计算的链接列表. 跟第二章的Link类类似, Stream实例响应请求它的第一个元素以及流剩下的元素. 跟Link类类似, Stream剩下的部分也是Stream. 跟Link不相似的是一个流剩下的部分只在它被查询的时候才计算, 而不是提前存储起来. 也就是说, 流剩下来的部分是懒计算的.
要实现这个懒运算, 流需要保存一个函数, 这个函数计算流剩下的部分. 无论何时函数被调用, 它返回的值会作为流的一部分被存储到一个叫做_rest的属性上, 以下划线来命名是为了标识它不应该被直接访问.
可访问的属性rest是一个属性方法, 它返回流剩下的部分, 在必要时进行计算. 有了这个设计, 流存储了如何计算流的剩余部分, 而不用总是明确地保存剩余的部分.
|
|
链表是通过嵌套表达式来定义的. 例如, 我们可以创建一个下面的表示具有元素1, 然后是元素5的Link:
|
|
同样地, 我们可以创建一个Stream表示相同的序列, Stream实际上并不计算第二个元素5, 直到剩余的stream被请求, 我们可以通过创建匿名函数来达到这个效果.
|
|
这里, 1是流的第一个元素, 然后接下来的lambda表达式返回一个函数来计算剩余的流.
访问链表r的元素跟流s的元素的过程是相似的. 然而, 5已经存在r里面, 而s是在第一次被请求的时候按需求来进行加法计算的.
|
|
而r的rest是一个具有两个元素的链表, 而s的rest则包括一个用于计算剩余部分的函数; 而它将会返回一个空的流的事实可能尚未被发现.
当一个Stream实例构建后, self._rest区域是None, 表示剩余的Stream部分尚未被计算. 当rest属性被通过点表达式请求, rest属性方法被调用就会触发self._rest = self._compute_rest()执行运算. 因为Stream的缓存机制, compute_rest函数只会调用一次, 然后会被丢弃.
compute_rest函数的基本属性是它不需要参数, 同时它返回一个Stream或者Stream.empty.
懒惰执行让我们有能力去用流来表示一个无限序列数据集. 例如, 我们可以表示增长的整数, 以任何first值开始.
|
|
当integer_stream第一次被调用, 它返回一个流, 这个流的first是在序列中的第一个整数. 然而, integer_stream实际上是递归的, 因为这个流的compute_rest会再次以一个增长了的参数来调用integer_stream. 我们说integer_stream是懒惰的是因为递归调用integer_stream只会在剩下整数流被请求的时候才会调用.
|
|
同样用来处理序列的高阶函数 –map以及filter– 同样也可以应用到流上去, 即使它们的实现必须要改成惰性地应用它们的参数函数. 函数map_stream映射函数到整个流上, 这会产生一个新的流. 内部定义的compute_rest函数确保在剩下的流被计算时函数会被映射到剩余的流中去.
|
|
流可以通过定义 一个compute_rest函数来应用过滤函数到剩余的流中来进行过滤. 如果过滤函数拒绝流的第一个元素, 剩下来的会马上被计算. 因为filter_stream是递归的, 剩下的流可能会被计算数次, 直到第一个有效的值被找到.
|
|
map_stream以及filter_stream函数展示了流处理的共同模式: 本地定义compute_rest函数每当在需要计算剩余部分的时候递归地应用过程函数到流剩余的部分中.
为了检查流里面的内容, 我们可以将第一个元素强制转为Python中的list类型.
|
|
这些便利函数允许我们去校验我们的map_stream实现, 一个简单的例子就是将从3到7的整数进行平方.
|
|
我们可以使用我们的filter_stream函数通过使用Eratosthenes的筛子来定义一个素数流, 它过滤整数流来移除所有是第一个元素的倍数的所有数字. 通过连续过滤每个素数,从流中删除所有复合数。
|
|
通过截断primes流, 我们可以列举任何素数的前缀
|
|
流与迭代器不同的是它们可以被传递给纯函数多次并且每次都返回相同的结果. 素数流通过将其转换成列表时并没有被"用完”. 也就是说, prime_numbers第一个元素在转换流的前缀为列表之后依旧是2.
|
|
就像链表提供简单的序列抽象实现一样, 流通过使用高阶函数实现懒惰计算从而提供简单, 功能强大的递归式数据结构.
4.3 声明式编程
除了流以外, 数据值通常也保存在大型的库中, 这个库称为数据库. 数据库由包含数据值的数据存储以及用于检索和转换这些值的接口. 每个存储在数据库中的值都被称为_记录_. 记录具有相似的结构且被分组成表. 记录使用查询(这是一种查询语言)来进行检索和转换. 到目前为止, 这是使用最广泛的查询语言被称为结构化查询语言或者SQL(读作 “sequel”).
SQL是声明式编程语言的一个例子. 声明并不直接描述计算, 而是描述期望的某些计算结果. 这是数据库系统查询解析器的作用是设计并执行计算过程来产出这样的结果.
这种交互与Python或Scheme这样的程序编程范例有很大的不同. 在Python, 计算过程是由程序员来直接指定的, 而声明式语言抽象程序细节, 而不是关注结果的形式.
4.3 表
SQL语言是标准化的, 但是大多数数据库系统会实现一些语言的自定义变体, 其带有某些专有功能. 在本文中, 我们会描述SQL的一个小的集合它被实现在Sqlite中. 你可以通过下载Sqlite或者使用在线的SQL解析器.
表, 也称为关联, 具有固定数量的命名和类型列, 表的每一行表示一个数据记录且每列都具有一个值. 例如, 一个城市的表可能会具有的列有latitude, longitude两者所持有的都是数值型的值, 还有一列为name所持有的值为字符串. 每一行通过它的纬度以及经度值来表示一个城市的坐标位置.
| Latitude | Longitude | Name |
|---|---|---|
| 38 | 122 | Berkeley |
| 42 | 71 | Cambridge |
| 45 | 93 | Minneapolis |
可以通过SQL语言中的select声明来创建一个表中的单个行, 行中值是被逗号给分隔开的, 后接一个关键词"as"以及紧随的每列的名称. 所有的SQL声明都以分号作为结尾.
|
|
第二行是输出, 每一条包含由竖线分隔开的列来组成.
多行表格可以通过_union_来构造, 这用来组合两个表的行. 左边的表格的列名在构建的表中使用. 而间隔在一行之内并不影响结果.
|
|
表格可以用create table声明来给定一个名称. 而这个声明也可以用来创建空表, 我们将会关注给定名称给一个已经通过select声明定义的存在的表格这种形式.
|
|
一旦一个表格被命名了, 这个名称可以用在select声明的from子句中. 表格中的所有列可以使用特殊形式的select *来展示.
|
|
4.3.2 Select声明
select声明定义一个新的表, 通过列出值在单一的一行或者更一般地通过from子句投影已经存在的表:
select [column description] from [existing table name]
结果表中的列通过一个以逗号分隔的表达式列表来描述, 对现有输入表的每一行执行运算.
例如, 我们可以创建两列的表, 这个表描述了每个城市距离伯克利的北部或者南部有多远. 每个纬度的每一度表示距离北方60海里.
|
|
列描述在语言中是一个表达式它分享了Python中的许多特性, 添加操作符如+以及%, 内建函数如abs以及round, 以及括号用来描述运算的顺序. 在这些表达式中的名称, 例如上面的latitude, 执行后得到列的值来形成数据行.
可选地, 每个表达式可以后接关键字as以及一个列的名称. 当整个表格被赋予一个名称时, 通常给每个列一个名称是很有用的, 这方便将来在select语句中被引用. 由简单名称描述的列将会自动命名.
|
|
Where子句, select声明也可以包含具有过滤表达式的where子句. 这表达式过滤映射的行. 只有经过滤表达式运算后得到的值为真的行才会被用于在结果表中生成一行记录.
|
|
Order子句. select声明也可以对结果表进行排序. order子句包含一个排序表达式, 这表达式对每个未经过滤的行执行运算. 这个表达式的结果值用作结果表的排序标准.
|
|
这些特性的组合允许select语句将输入表的各种映射表达到相关的输出表中.
4.3.3 连接
通常来说, 数据库会包含多个表同时查询可以要求包含在不同的表中的信息来计算出期望的结果. 例如, 我们可能会有第二表描述了不同城市的平均日高温.
|
|
通过将多个表连接在一起来组合数据, 这是数据库系统的基本操作. 有很多方法来进行连接, 所有都是密切相关的, 但是在本文中我们会只专注于一个方法. 当表被连接时结果表包含所有输入的表组合而成的新的行. 如果两个表被连接同时左边的表具有m行, 右边的表具有n行, 那么连接后的表就会具有m*n行. 连接在SQL中的表达是通过在select语句中的from子句中用逗号分隔表格名称来实现的.
|
|
连接一般会伴随有where子句来表达两个表之间的关系. 例如, 如果我们想要收集数据到一个表中, 这个表允许我们关联纬度以及温度, 我们会从连接中选择那些两个表中都提及到的城市来组成行. 在cities表中, 城市的名称被保存在名为name的列中. 在temps表中, 城市名称被保存在名为city的列中. where子句在连接表中选择那些值相等的行. 在SQL, 使用单个=符号来测试数字等式.
|
|
表可能会具有重叠的列名称, 因此我们需要一种通过表来消除列名称歧义的方法, 一个表也可能与它自己来进行连接, 因此我们需要一种方法来消除表名称的歧义. 为了这样做, SQL允许我们在from子句中用as关键字来为表格起别名并通过使用点表达式来在特定表格中引用列名称. 下面的select语句计算两个不相等的城市的温度差. 在where子句中具有按之母顺序的约束确保每一对数据只会在结果中出现一次.
|
|
我们在SQL中组合表的两种方法, 连接以及合并(join以及union), 允许语句具有极大的表现力.
4.3.4 解释SQL
为了创建迄今为止介绍的一个SQL子集的解析器, 我们需要创建表格的表示, 用文本写成的语句的解析器以及解析语句的执行器. sql解析器的例子介绍了所有这些部分, 提供简单但是能演示功能的声明式语言解析器.
在这个实现中, 每个表具有它自己的类, 在表中的每行数据通过这个表格类的实例来进行表示. 行在表中的每一列都具有一个属性, 同时, 表格是一系列的行.
表格的类是使用Python标准库中的collections包中namedtuple函数来创建的, 它会返回一个新的tuple的子类, 并给元组中的每个元素命名.
想一下来自前面章节的cities表, 表示如下.
|
|
下面的Python语句构造了这表格的表示
|
|
select语句的结果可以用序列操作来进行解析. 回想一下来自前面章节的distances表, 表示如下.
|
|
这个表格是由cities表格中的name以及latitude列产生的. 这结果列表可以通过在输入表的行上映射函数来形成, 这个函数为每一个CitiesRow返回DistancesRow.
|
|
我们的SQL解析器的设计概括了这个方法. select语句表示为由select子句构造的类Select的实例.
|
|
execute方法连接输入表, 过滤并排序结果行, 然后映射函数make_row调用到这些结果行中. make_row函数是在Select构造器中通过调用create_make_row来创建的, 这个高阶函数为结果表创建一个新的类并定义如何将输入行投影到输出行. (这个函数具有更多错误处理以及特殊情况的版本出现在sql中.)
|
|
最后, 我们需要定义join函数来创建输入行. 给定一个env字典包含现有表(行的列表)并以它们的名字作为key值, join函数将所有行的组合, 用itertools包中的product函数组合到输出表中. 它映射一个叫做make_env的函数到已经连接完成的行当中去, 这个函数将每个行的组合转换为字典, 以便它可以用来执行表达式. (这个函数具有更多错误处理以及特殊情况的版本出现在sql中)
|
|
上面, row._fields求包含该行的表的列名称的值. _fields属性的存在是因为row的类型是namedtuple类.
我们的解析器已经足够执行select语句了. 例如我们可以计算从"Berkeley"到其他所有城市的纬度距离, 并以它们的经度来排序.
|
|
上面的例子等于接下来的SQL语句.
|
|
我们也可以保存这个结果表到环境中并将它跟cities表进行连接, 并检索每个城市的经度.
|
|
上面的例子等同于下面的SQL语句.
|
|
完整的sql例子程序也包含一个用于select语句的简单解析器, 以及create table和union的execute方法. 解析器可以正确地执行所有的SQL语句包括本文目前为止所包含的. 而这个简单的解析器只实现了少量完整的结构化查询语言, 它的结构演示了序列处理操作以及查询语言之间的关系.
查询计划. 声明式语言描述了结果的形式, 但是没有明确地描述这个结果应该如何被计算得到. 这个解析器总是连接, 过滤, 排序, 然后投影输入行用以计算结果行. 然而, 更有效率的计算相同结果的方式可能是存在的, 同时查询解析器也可以自由地在它们之间做选择. 为计算查询结果选择高效过程也是数据库系统的核心功能.
例如, 思考一下上面最后的选择语句. 并非是计算连接后的cities以及distances然后过滤出结果, 而是相同的结果可能首先对两个表都以name列来进行排序, 然后只连接具有相同名称的行, 以线性的方式过一遍已经排序过的行. 当表格是巨大的时候, 查询计划选择可以具有很大的效率增益.
4.3.5 递归选择语句
选择语句可以选择性地包含with子句来生成以及命名另外的用来计算最终结果的表. select语句的完整语法, 不包括联合(unions), 具有以下的形式:
with [tables] select [columns] from [names] where [condition] order by [order]
我们已经展示了[columns]和[names]的允许值. [condition]以及[order]是可以用来执行计算输入行的表达式. [tables]部分是一个用逗号分割的用来描述表格形式的列表.
[table name]([column names]) as ([select statement])
任何select语句都可以被用来在[tables]中描述一个表
例如, 下面的with子句声明了一个表states包含城市以及它们的状态. select语句计算同一州内的城市对.
|
|
一个定义在with子句中的表可能会具有递归的情况, 它根据其他输出行来定义输出行. 例如, 下面的with子句定义一个具有5到15的整数的表, 而奇数值会被选择并进行平方.
|
|
多个表可以被定义在with子句中, 用逗号隔开. 下面的例子计算所有的来自表中的整数的毕达哥斯拉三角数, 它们的平方, 以及平方对的和. 毕达哥斯拉三角数由整数a, b以及c来组成这样的公式\(a^2 + b^2 = c^2\)
|
|
设计递归查询涉及到确保每个输入行的相应信息可用于计算输出行. 例如, 计算斐波那契数, 输入行为了要计算出下一个元素需要的不仅是当前元素, 同时前一个元素也需要.
|
|
这些例子证明了递归是强大的组合手段, 甚至是在声明式语言中.
建造字符串. 两个字符串可以通过使用在SQL中的||操作符级联成更长的字符串.
|
|
这个特性可以用来通过短语从而构造句子. 例如, 构造英文句子的一种方式是级联一个主题名词短语, 一个动词, 以及一个对象名词短语.
|
|
作为练习, 使用一个本地递归表来构建句子, 如: “the dog that chased the cat that chased the bird also chased the bird.”
4.3.6 聚合与分组
到目前为止我们介绍的select语句可以连接, 投射, 操纵单个行. 除此之外, select语句还可以执行多行聚合操作. 聚合函数max, min, count以及sum返回列中的最大, 最小, 数字以及总和值. 多种聚合函数可以通过定义多个列应用到相同的行集合里面. 只有包含在where子句中的列才会被认为是在这个集合中.
|
|
distinct关键字确保聚合中没有包含列中重复的值. 在animals表中的legs只出现了两个不同的值. 特殊的count(*)句法统计行的数量.
|
|
每一个select语句都产出具有一行数据的表. select语句中的group by以及having子句是用来将行分成组并仅选择组的一个子集. 任何在having子句中的聚合函数或者列描述会被单独地应用到每一组, 而不是表中的整个行的集合.
例如, 计算来自这个表的所有四条腿以及两条腿的动物中重量最大的那个, 下面的第一个语句将狗和猫组合在一起为一个组, 同时鸟作为一个分组. 结果表明最大重量的两条腿的动物是3(鸟), 而对于四条腿的动物则是20(狗). 第二个查询列出了至少有两个不同名称的legs列中的值.
|
|
多列以及完整表达可以出现在group by子句中, 同时, 组将为每个独特的组合值形成结果. 通常, 用在分组的表达式也会出现列描述, 因此这很容易去确定每个组产生的结果行.
|
|
having作为where的子句可以包含相同的过滤, 但是也可以包含调用聚合函数. 为了最快地执行的同时清晰使用这门语言, 基于其内容过滤单个行的条件应显示在where子句中, 而having子句应该只在聚合需要条件语句时使用(例如, 确定组的最小的count)
当使用group by子句, 列描述可以包含非聚合的表达式, 在某些情况下, SQL解析器将从包含聚合的另一列对应的行中选择值. 例如, 下面的语句给出最大weight的动物的name.
|
|
然而, 每当对应于聚合的行是不确定的时候(例如, 当用count而不是max聚合时), 选择的值可能是任意的. 为了最清晰同时最可预测地使用这门语言, select语句包含group by子句的话至少应该包含聚合列同时只有当非聚合列的内容可以从聚合中预测时, 才去包含它.
4.4 逻辑编程
在这一章中, 我们介绍一个声明式查询语言, 它叫做logic, 特别为本文来设计的. 它建立在Prolog以及在计算机程序构造与解析声明式语言之上. 数据记录是作为Scheme列表来表示的, 同时查询表示为Scheme值. logic解析器是一个基于前一章的Scheme项目之上的完整实现.
4.4.1 事实和疑问
数据存储记录代表系统中的事实. 查询解析器的目的是直接检索从数据库记录中抽取的事实的集合, 以及使用逻辑推理从数据库中推断出新的事实. 在logic语言中的fact语句包含一个或多个遵循关键字fact的列表. 一个简单的事实是单一的一个列表. 对美国总统感兴趣的狗饲养员可以使用logic语言记录她收集的狗的家谱, 如下:
|
|
在Scheme表达式中, 每个fact不是一个应用程序, 而是声明的关系. “Abraham狗是Barack狗的父亲,” 声明第一个事实. 关系类型不需要提前定义. 关系并不是用来应用, 而是用于匹配查询.
一个查询也由一个或多个列表组成但是以关键字query开头. 一个查询可能包含变量, 它以问号符号作为开头. 变量通过查询解析器与事实进行匹配.
|
|
查询解析器以Success!作为响应来表明查询匹配某些事实. 接下来的几行展示变量?child的替换匹配在数据库中查询的事实.
复合事实. 事实可能也会包含变量以及多个子表达式. 一个多表达式事实从结论开始, 其次是假设. 要想结论是真实的, 那么所有的假设必须要满足:
(fact <conclusion> <hypothesis0> <hypothesis1> ... <hypothesisN>)
例如, 关于孩子的事实可以以已经存在数据中的父级的事实为基础来声明:
(fact (child ?c ?p) (parent ?p ?c))
上面的事实可以被读作: “?c 是 ?p 的孩子. 倘若 ?p 是 ?c 的父级.” 一个查询现在可以被索引到这个事实:
|
|
上面的查询需要查询解析器来组合那些各个父级事实被定义为fillmore的子级的事实. 语言的用户不需要知道这些信息是如何被组合的, 只需要知道结果具有特定的形式. 这是由查询解析器来证明在给定的可用事实下(child abraham fillmore)是对的.
查询不需要包括变量; 它可能只是简单地验证一个事实:
|
|
查询如果没有匹配任何的事实会返回失败(消息):
|
|
否定. 我们可以用关键词not来检查查询语句是否没有匹配任何的事实:
(query (not <relation>))
如果<relation>失败, 则查询成功, 如果<relation>成功, 则查询失败. 这一思想被称为否定为失败.
|
|
有时候, 否定为失败对于期望否定能够有效是有悖常理的. 想一下下面的查询的结果:
(query (not (parent abraham ?who)))
为什么这个查询会失败? 可以肯定的是这里有许多符号可以绑定到这个被保留的变量?who中. 然而, 否定的步骤表明我们首先检查的关系是(parent abraham ?who). 这个关联是成功的, 因为?who可以被绑定到barack或者clinton中. 由于这个关联成功了, 这个关联的否定则必然失败.
4.4.2 递归事实
logic语言也允许递归事实. 也就是说, 事实的结论可能取决于一个假设, 这个假设包含了相同的符号. 例如, 祖先关系被定义为两个事实. 某些?a如果是?y的父级或者是?y的祖先的父级, 则它是?y的祖先.
|
|
单个查询可以列出所有的herbert的祖先:
|
|
复合查询. 查询可能具有多个子表达式, 在这种情况下, 所有这些都必须同时通过将符号分配到变量来同时满足. 如果一个变量在一次查询中出现多于一次, 那么它必须在每个上下文中都具有相同的值. 接下来的查询查找herbert以及barack的共同祖先:
|
|
递归事实可能需要一长串的推论来将查询与数据库中的现有事实相匹配. 例如, 要证明事实(fillmore herbert的祖先), 我们必须要证明每一个具有继承性的下列事实:
|
|
通过这种方式, 某个事实可以意味着一大堆额外的事实, 甚至是无限多的, 只要这个查询解析器能够发现它们.
分级事实. 到目前为止, 每个事实以及查询表达式都是符号列表. 除此之外, 事实以及查询列表可以包含列表, 提供了一种方式来表示分级数据. 每只狗的颜色可能会与名称一起存储在附加记录中:
|
|
查询可以表达层次结构的完整结构, 或者它们可以将变量匹配到整个列表:
|
|
数据库中的大部分功能在于查询解析器在一次查询中将多种事实连接的能力. 下面的查询寻找所有的以一对形式组成的狗, 其中一个是另一个的祖先, 并且它们共享同一种颜色:
|
|
变量可以在分层记录中引用列表, 而且还使用点符号. 一个变量紧跟着一个点符号将会匹配列表中的其他的事实. 带点的列表可以出现在事实或者查询中. 下面的例子通过列出它们的祖先链来构建狗的血统. 年轻的barack循着著名的总统宠物的这条线上:
|
|
声明式或者逻辑式编程可以以显著的效率表达事实之间的关系. 例如, 如果我们希望表达两个列表可以附加形成一个更长的列表以第一个列表的元素为先随后跟着的元素是第二个列表的, 为此我们声明两个规则. 首先, 基础情况是声明将空列表添加到任何列表中并返回这个列表:
(fact (append-to-form () ?x ?x))
接着, 一个递归事实声明具有第一个元素为?a以及余下元素?r的列表附加到列表?y中来形成一个列表, 它具有的第一个元素为?a以及余下被附加的?z. 为了保持这种关系, 它必须要是?r和?y附加形成?z这种情况:
(fact (append-to-form (?a . ?r) ?y (?a . ?z)) (append-to-form ?r ?y ?z))
使用这两个事实, 查询解析器可以计算附加任意两个列表到一起的结果:
|
|
此外, 它还可以计算?left以及?right的所有可能的列表对来附加形成列表(a b c d e):
|
|
尽管看起来我们的查询解析器很智能, 但我们可以看到它通过一个简单的操作重复很多次来查找这些组合: 匹配在环境中包含变量的两个列表.
4.5 统一
本节描述一个能够执行推理logic语言的查询解析器的实现. 这个解析器是一个一般问题的解决者, 但是在它可以解决的问题的规模以及类型上具有实质性的限制. 存在着更加复杂逻辑编程语言, 但是高效推理程序的构建仍然是计算机科学积极研究的课题.
通过查询解析器执行的基本操作被称为统一. 统一是匹配查询到一个事实的一般方法, 每一个都可能包含变量. 查询解析器反复地应用这个操作, 首先去匹配原始的查询来对做出事实的结论, 然后匹配事实对于在数据库中的其他结论的假设. 在这样做之后, 查询解析器通过所有与事实查询有关的事实之间来执行搜索. 如果它找到一个方法来支持使用赋值给变量进行查询, 它会将该工作作为成功的结果返回.
4.5.1 模式匹配
为了返回匹配查询的简单事实, 解析器必须要匹配包含不具有事实的变量的查询. 例如, 查询(query (parent abraham ?child))以及如果变量?child具有值barack那么事实(fact (parent abraham barack))与之匹配.
一般来说, 一个模式匹配某些表达式(一个可能的嵌套Scheme列表), 如果有变量名与值的绑定, 将这些值转换为模式, 则会生成表达式.
例如, 表达式((a b) c (a b))匹配模式(?x c ?x)其中?x绑定到值(a b). 相似的表达式匹配模式((a ?y) ?z (a b))其中变量?y绑定到b同时?z绑定到c.
4.5.2 代表事实和查询
下面的例子可以通过引入提供的logic例子程序来复现.
|
|
所有的查询以及事实都使用在逻辑语言中的Scheme列表来表示, 使用之前章节中相同的Pair类以及nil对象. 例如, 查询表达式(?x c ?x)是被表示为嵌套的Pair实例.
|
|
就像在Scheme项目中一样, 将符号绑定到值的环境用Frame类的实例来表示, 它具有一个称为bindings的属性.
在logic语言中执行模式匹配的函数被叫做unify. 它接受两个输入, e和f, 以及一个记录了将变量绑定到值的env环境.
|
|
上面, 来自unify的返回值True表明模式f能够匹配表达式e. 结果统一的结果被记录在以绑定到约束在env中的(a b)到?x.
4.5.3 统一算法
统一是概括模式匹配中尝试去寻找两个可能都具有变量的表达式之间的映射. unify函数通过一个递归过程在两个表达式的相应部分执行统一直到遇到矛盾或者建立对所有变量的可行约束来实现统一.
让我们以一个例子来作为开始, 模式(?x ?x)可以匹配模式((a ?y c) (a b ?z))因为有一个没有变量的表达式可以匹配它们两者: ((a b c) (a b c)). 统一通过下面的步骤来识别这一解决方案:
- 匹配每个模式的第一个元素, 变量
?x被绑定到表达式(a ?y c). - 匹配每个模式的第二个元素, 首先变量
?x被它的值给替代. 然后, 通过绑定?y到b以及?z到c使得(a ?y c)跟(a b ?z)相符合.
因此, 传递给unify的绑定环境包含了条目?x, ?y, 以及?z:
|
|
统一的结果可能会绑定变量到一个表达式, 这个表达式本身也可能包含变量, 就像我们上面看到的?x绑定为(a ?y c). bind函数递归且重复地在一个表达式上绑定它们的值到所有的变量上直到没有遗留需要绑定的变量.
|
|
一般来说, 统一通过检查几个条件来执行. unify的实现直接遵循下面的描述.
- 输入
e以及f如果它们两者是变量则它们会被值给替换 - 如果
e以及f相等, 统一则成功执行. - 如果
e是一个变量, 统一成功执行同时e被绑定到f. - 如果
f是一个变量, 统一成功执行同时f被绑定到e. - 如果两者都不是一个变量, 都不是一个列表, 同时它们也不相等, 那么
e以及f就不能统一, 因此统一执行失败. - 如果这些情况都不成立, 那么
e和f都是pairs, 因此统一则需要在它第一和第二个对应的部分上执行.
|
|
4.5.4 证明
思考逻辑语言的一种方式是在正式的系统中以断言来进行证明. 每一个声明的事实都是建立在一个正式系统上的公理中, 同时每个查询必须要由查询解析器来在这些公理之上建立. 也就是说, 每个查询声明对其变量有一些赋值, 使得它的所有子表达式同时遵循系统的事实. 而查询解析器的角色就是去验证的确是这样的.
例如, 给定有关狗的一系列事实, 我们会断言在这里Clinton以及一条棕色的狗具有相同的祖先. 查询解析器只输出Success!如果它能够确定这个断言是真的. 作为副产品, 它告知我们这个共同祖先以及棕色的狗的名字:
|
|
展示在结果中的三个任务中的每一个都是用来跟踪在给定的事实下来更大地证明查询是真实的. 一个充分的证明包括所有使用的事实, 例如包含(parent abraham clinton)以及(parent fillmore abraham).
4.5.5 搜索
为了在系统中已经建立的事实中建立一个查询, 查询解析器在所有可能的事实空间中执行一个查询. 统一是原始操作, 它对两个表达式进行模式匹配. 在查询解析器中的搜索过程选择用哪个表达式来进行统一, 以便找到链接在一起以建立查询的一组事实.
search递归函数为logic语言实现查询过程. 它将在查询中的Scheme列表中的clauses作为输入, 环境env包含当前绑定了值(初始为空)的符号, 而且depth规则链也已经连接到一起了.
|
|
满足所有子句的查询同时也开始于第一个子句, 在我们的第一个子句被否定的特殊情况下, 不是试图将查询的第一个子句与事实统一起来, 而是我们通过递归调用search来检查这里没有这样的统一的可能. 如果这个递归调用没有返回任何东西, 我们以剩余的子句来继续这个查询过程, 如果统一是可能的, 那我们就立即失败了.
如果我们的第一个子句没有被否定, 那么对于数据库中的每一个事实, search都尝试去将事实的第一个子句跟查询的第一个子句统一起来. 统一是在新的环境env_head中执行的. 作为统一的副作用, 变量被绑定到env_head中的值中.
如果统一成功了, 那么, 子句匹配当前规则的结论. 接下来的for语句尝试去建立规则的假设, 因此结论可以被建立. 在这里, 递归规则的假设将被递归地传递以便建立进行search.
最后, 对每个fact.second的成功搜索, 结果那环境绑定到env_rule. 给定这些值的绑定到变量, 最后的for语句搜索建立初始查询的剩余子句. 任何成功的结果都是通过内部的yield语句返回的.
唯一名称. 统一操作假设在e以及f之间没有共享变量. 然而, 我们常常在logic语言的事实以及查询中复用变量名. 我们不会想将一个事实中的?x与另外一个事实中的?x混淆; 这些变量是不相关的. 在一个事实传入到统一前确保名称是不迷惑的, 其变量名称由使用rename_variables函数通过为事实附加一个唯一的整数替换为唯一的名称.
|
|
其余的细节, 包括在logic语言中的用户接口以及各种帮组函数的定义, 都出现在logic的例子中.
4.6 分布式计算
大型数据处理程序通常会在多个计算机之间对有组织的活动进行协调. 分布式计算程序是一个在多个相互连接但独立计算机之间联合协调计算过程的程序.
不同的计算机在某种意义上讲是独立的因为它们并不直接共享内存. 相反, 它们用_消息_来彼此通信, 通过网络将消息从一台计算机传递到另一台计算机.
4.6.1 消息
在计算机之间发送的消息是一系列的位. 发送以及接收的计算机都必须要对消息的含义进行协商来使得交流能够成功. 很多消息协议指定消息必须遵循特定的格式使得在特定位置的位表示特定的条款. 其他使用特殊一个位或几个位序列来界定消息的各个部分, 就像在编程语言中用标点符号来界定子表达式.
消息协议并非特定的程序或者软件库. 相反它们是可以被应用到多种程序中的规则, 甚至可以用不同的编程语言来编写. 因此, 具有极大不同的软件系统可以简单地通过遵从支配整个系统的消息协议来参与到相同的分发系统中.
TCP/IP协议. 在网络上, 消息使用网络协议(IP)来从一个机器到另一个机器上传递, 这个协议具体说明了如何在不同的网络中传输包来允许全球网络通信. IP是设计在假设网络内部本身在任何时间点以及动态结构下都是不值得信任的, 此外, 它不会假设有任何通信上的中部跟踪或者监控的存在. 每一个包都包含一个头部, 这个头部包含目的IP地址, 以及其他消息. 所有的包都是在整个网络中向着目的地使用简单的路由协议以最大努力交付为基础来进行转发的.
这个设计在通讯上施加限制. 包传输使用IP模式实现(IPv4以及IPv6)其具有最大大小为65,535位. 更大的数据值必须切分为多个数据包. IP协议并不保证包会以其发送的相同的顺序来被接收. 一些包可能会丢失, 某些包可能会被传输多次.
传输控制协议是根据IP协议来抽象定义的用于提供可靠有序传输任意大小字节流的协议. 这个协议通过正确排序IP协议的正确的包来提供这个保证, 删除重复以及请求丢失了的包. 这种改进的可靠性以牺牲延迟为代价, 即将消息从一个点发送到另一个点所需的时间.
TCP将流数据切分为TCP段, 每个都包含前面带有标题的数据的一部分, 其包含序列以及状态信息来支持有序, 可靠的数据传输. 某些TCP段不包含一点数据, 只是用于建立或者结束两个计算机之间的沟通通讯.
在两台计算机A以及B之间建立链接需要执行一下三个步骤:
- 发送请求到
B的端口来建立TCP链接, 提供一个_端口号_来指定响应发送的端口号. B发送一个响应到A指定的端口号并等待它的响应被确认.A发送响应确认, 验证数据可以进行双向传输.
在进行这三步"握手"之后, TCP连接就建立了, A以及B可以互相之间发送数据. 终止TCP连接也需要一系列的步骤来进行, 其中客户端和服务器端都请求并确认连接的结束.
4.6.2 客户端/服务器架构
客户端/服务器架构是从中央源分配服务的一种方式, 服务器提供一个服务同时多个客户端与服务器通信来消费该服务. 在这中架构下, 客户端以及服务器扮演不同的角色. 服务器的角色是去响应来自客户端的服务请求, 而客户端的角色是去发起请求以及使用服务器的响应来执行某些任务. 下面的图表说明了这个架构.

使用这种模型且最有影响力的是现代万维网(World Wide Web). 当网络浏览器展现网页的内容时, 运行在独立计算机上的多个程序使用客户端/浏览器架构来进行交互. 这一节介绍请求网页的过程用以说明客户端/服务器分布式系统中的中心思想.
角色. 在网络用户计算机上的网络浏览器应用当其请求一个网页的时候扮演的是客户端的角色. 当从一个因特网上的域名请求内容时, 例如www.nytimes.com, 它必须要跟至少两个不同的服务器进行通信.
用户最开始从域名服务器(DNS)请求位于该域名的的计算机的互联网协议(IP)地址. DNS提供映射域名到IP地址的服务, IP地址是因特网上机器的数字标识符. Python可以直接使用套接字(socket)模块提出这样的请求.
|
|
接着客户端会从位于对应IP地址的服务器请求网页的内容. 在这种情况下的响应是HTML文件, 这个文件包含标题和今日新闻的文章摘要, 以及表达并指出网络浏览器应该如何在客户界面上显示内容. Python可以使用urllib.request模块来发起两个请求去获取这些内容.
|
|
收到此回复, 浏览器为图片, 视频以及页面的其他部分发起额外的请求. 这些请求被发起是因为原始的HTML文件包含有额外内容的地址以及如何将它们内嵌进页面的描述.
HTTP请求. 超文本传输协议(HTTP)是一个使用TCP实现的协议, 它是用来管理万维网(WWW)通讯的协议. 它假设网络浏览器以及网络服务器之间是客户端/服务器架构形式. HTTP指定浏览器与服务器之间的消息交换的格式. 所有网络浏览器使用的是HTTP格式来从网络服务器请求页面, 同时所有的网络服务器使用HTTP格式来返回它们的响应.
HTTP请求具有几种类型, 最常用的是使用GET请求指定的网页. GET请求指定一个位置. 例如, 输入地址http://en.wikipedia.org/wiki/UC_Berkeley到Web浏览器中向en.wikipedia.org所在的Web服务器的端口80发起一个HTTP的GET请求获取位于/wiki/UC_Berkeley的内容.
服务器返回HTTP响应:
HTTP/1.1 200 OK
Date: Mon, 23 May 2011 22:38:34 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
Last-Modified: Wed, 08 Jan 2011 23:11:55 GMT
Content-Type: text/html; charset=UTF-8
... web page content ...
在第一行, 文本200 OK表明在响应请求的过程中没有错误发生. 在头部的后续行中给定关于服务器, 日期以及返回的内容类型的信息.
如果你输入一个错误的web地址或者点击一个坏了的地址, 你可能会看到这样的消息, 如这个错误:
404 Error File Not Found
这意味着服务器返回一个以下面所示开始的HTTP头:
HTTP/1.1 404 Not Found
数字200以及404是HTTP响应码. 一组固定的响应码是消息协议的共同特征. 协议的设计者尝试去预测常用的会通过协议发送并分配固定码以减少传输数据量的大小同时建立公共消息语义的消息. 在HTTP协议中, 200响应码表明成功, 而404指示资源没有找到的错误. 其他各种各样的响应码存在于HTTP1.1标准中.
模块化客户端和服务器的概念是强大的抽象. 服务器有可能同时对多个客户端提供服务, 而且客户端消费该服务. 客户端不需要知道服务是如何被提供的细节, 或者它们接收的数据是如何被存储以及计算的, 以及服务器不需要知道它的响应将会如何被使用.
在Web上, 我们认为客户端以及服务器位于不同的机器上, 但即使是在单一的机器上的系统也可以具有客户端/服务器架构. 例如, 来自计算机上的输入设备的信号通常需要可用于计算机上运行的程序. 程序是客户端, 它会消耗鼠标以及键盘的输入数据. 操作系统的设备驱动程序是服务器, 接受物理信号同时为它们提供可用的输入. 此外, 中央处理单元(CPU)以及专门的图形处理单元(GPU)通常也参与进客户端/服务器架构, 其中CPU作为客户端而GPU则作为图形的服务器.
客户端/服务器系统的缺点是服务器是单点故障. 它是唯一具有发放服务能力的组件. 客户端的数量可以是任意的, 彼此间可以互换, 并根据需要加进来或者除去.
另一个客户端-服务器系统的缺点是如果客户端过多的话则计算资源会变得稀缺. 客户端增加对系统的需求, 而不贡献任何计算资源.
4.6.3 点对点系统
客户端/服务器模式很适合面向服务的情况. 然而, 对于还有其他计算目标的系统而言更加平等的分工是一个更好的选择. 术语_点对点_是用来形容分布式系统的, 其中的工作均分在系统的所有部分中. 所有的计算机都发送并接收数据, 同时它们都贡献一定的处理能力以及存储. 随着分布式系统的规模越来越大, 其计算资源的能力也随之上升. 在一个点对点系统中, 系统的所有部分都贡献一些处理能力和内存到分布式计算中.
在所有的参与者当中均分劳动量是识别点对点系统的特征. 这意味着点需要能够彼此之间进行可靠的通信. 为了确保消息能够准确到达目的地, 点对点系统需要具有一个有组织的网络结构. 在这些系统中的组成部件合作维护足够的关于其他部件的位置的信息来发送消息到目的地.
在某些点对点系统中, 保持网络健康的工作是由一组专门的组件来进行的. 这样的系统并不是纯粹的点对点系统, 因为他们具有不同类型的组件来提供不同的功能. 这样的部件像脚手架一样支撑点对点系统: 它们帮助网络保持连接, 它们维护关于不同计算机位置的信息, 同时它们帮助新加入的成员在它们的邻居中占据它们自己的位置.
最常用的点对点系统应用是数据传输以及数据存储. 对于数据传输来说, 每个在系统中的计算机都帮助在网络上发送数据. 如果目的地计算机在是在某个特定的计算机附近, 那么这个计算机也会帮助发送数据. 对于数据存储而言, 数据集可能对于任何单台计算机来说都是过于巨大的, 或者数据过于贵重无法仅存储于一个计算机上. 每个计算机都存储数据的一小部分, 同时相同的数据可能有多个副本分布在不同的计算机上. 当一个计算机出现故障时, 其上的数据可以从其他副本恢复, 并在替换到达时放回去.
Skype, 语音以及视频聊天服务, 是点对点架构的数据传输应用的一个例子. 当两个在不同计算机上的人进行Skype会话时, 他们的对话会通过点对点网络进行传输. 该网络由运行Skype应用程序的其他计算机组成. 每个计算机都知道一些临近的其他计算机的位置. 一个计算机通过传输数据到它的邻居节点来帮助发送数据包到目的地, 而它的邻居节点也会传输数据到相应的邻居节点等等, 一直到包到达它的预订目的地. Skype并不是一个纯粹的点对点系统, 超级节点的脚手架网络负责登录和注销用户. 维护有关于计算机位置的信息以及在用户进入和退出时修改网络结构.
4.7 分布式数据处理
分布式系统通常用来收集, 访问, 以及操作大型数据集. 例如, 前面章节描述的数据库系统可以操作保存在多个机器上的数据集. 没有一台机器可能包含响应查询所需的数据, 因此需要通信才能对请求进行服务.
这一节探讨一个典型的大数据处理场景, 其中由于数据集太大而不能被单个机器处理, 而是分布在许多机器之间, 每个机器处理数据集中的一部分. 计算的结果必须经常在机器之间聚合, 因此一台机器的计算结果可以与其他机器组合. 为了协调这种分布式数据处理, 我们会讨论一个称为MapReduce的编程框架.
使用MapReduce来创建一个分布式数据处理应用结合了本文中提出的许多想法. 应用程序用纯函数表示, 用于映射大型数据集, 然后将映射的值的序列不断减少直到得到最终结果.
函数式编程中的熟悉概念用于MapReduce程序中具有巨大的好处. MapReduce要求用于映射和减少数据的函数是纯函数. 一般来说, 仅在纯功能方面表达的程序在如何执行方面具有很大的灵活性. 子表达式可以并行执行并以任意的顺序计算而不影响最终结果. 一个MapReduce应用能够并行运行许多纯函数, 重新排序在分布式系统中有效执行的计算.
MapReduce的主要优势是它把分布式数据处理应用程序的两个部分之间的问题进行了分离:
- map以及reduce函数用于处理数据并将结果进行组合.
- 机器之间的沟通和协调.
协调机制处理分布式计算中出现的许多问题, 例如, 机器故障, 网络故障, 以及进度监控. 而管理这些问题为MapReduce应用程序引入了一些复杂性, 而这些复杂性没有暴露给应用程序开发人员. 相反, 构建一个MapReduce应用只需要指定上面(1)中提到的map以及reduce函数即可; 分布式计算的挑战是如何通过抽象来实现隐藏.
4.7.1 MapReduce
MapReduce框架假定输入是巨大, 无序的任意类型的输入值流. 例如, 每个输入可能是某些浩瀚的语料库中的一行文本. 计算过程分为三个步骤.
- map函数应用到每个输入中, 它会输出零个或者更多任意类型的中间键值对.
- 所有中间键值对都按照键来进行分组, 因此具有相同键的对可以被减少合并在一起.
- reduce函数对给定的键
k的值组合在一起; 它会输出零个或者更多的值, 它们各自与最终输出中的k相关联.
为了执行这个计算, MapReduce框架创建在计算机中执行各种角色的任务(可能在不同的机器上). _map_任务会应用map函数到某些子集的输入数据上并输出中间键值对. _reduce_任务通过键来排序并组合键值对, 然后应用reduce函数到每个键的值上. 所有在map以及reduce任务之间的通信由框架来处理, 按键分组中间键值对的任务也是如此.
为了在MapReduce应用中利用多台机器, 多个mappers会并行运行在一个map周期中, 而多个reducers并行运行在一个reduce周期中. 在这些周期之间, sort周期通过对它们进行排序来将键值对组合在一起, 因此具有相同键的所有键值对都相邻.
思考下关于计算文本语料库中的元音数量的问题. 我们可以使用MapReduce框架通过选择合适的map以及reduce函数来解决这个问题. map函数接受一个文本行作为输入并输出键值对, 键值对中元音作为键而值则是数量. 从输出中省略零计数:
|
|
reduce函数在Python中是内建的sum函数, 它以一个建立在值(对于给定键的所有值)之上的迭代器作为输入并返回它们的总数.
4.7.2 本地实现
为了详述MapReduce应用, 我们需要实现一个可以让我们插入map以及reduce函数的MapReduce框架. 在接下来的部分中, 我们会使用开源的Hadoop实现. 在这一部分, 我们会使用Unix操作系统内建的工具开发一个最小实现.
Unix操作系统在计算机的底层硬件以及用户程序中创建了一个抽象屏障. 它为程序相互之间的沟通提供了一个机制, 尤其是允许一个程序消耗另一个程序的输出, 在他们关于Unix编程精粹的文本中, Kernigham以及Pike宣称, “系统的能力更多地来自于程序之间的关系而不是程序本身.”
Python文件可以通过在第一行添加一个注释来表明该程序应该使用Python3解析器执行来从而将其转换成Unix程序. Unix程序的输入是一个可迭代对象, 称之为_标准输入_并可通过sys.stdin来访问. 在这个对象之上访问会产生字符串值的文本行. Unix程序的输出被称为_标准输出_并可通过sys.stdout来访问. 内建的print函数写入一行文本到标准输出中. 下面的Unix程序将其输入的每一行的顺序反转后写入到其输出中:
|
|
如果我们保存这个程序到一个名为rev.py的文件中, 我们可以将它作为一个Unix程序来执行. 首先, 我们需要告诉操作系统我们已经创建了一个可执行程序:
$ chmod u+x rev.py
接下来, 我们将一些输入传输到这个程序中. 一个程序的输入可以来自于另一个程序. 要达到这个效果我们会使用|符号(称为"管道/pipe”), 它用来将位于管道之前的程序的输出用作位于管道之后的程序的输入. 程序nslookup输出IP地址的主机名称(这个例子中用的是纽约时报):
|
|
cat程序用于输出文件的内容. 因此, rev.py程序可以用来接收rev.py文件本身的内容:
|
|
这些工具已经足够让我们实现一个基本的MapReduce框架. 这个版本只有单一的map任务以及单一的reduce任务, 它们都是用Python实现的Unix程序. 我们使用下面的命令来运行整个MapReduce应用:
|
|
mapper.py以及reducer.py程序必须实现map函数以及reduce函数, 以及一些简单的输入和输出行为. 例如, 为了实现上面说到的统计元音数量的程序, 我们会编写接下来的count_vowels_mappers.py程序:
|
|
此外, 我们还会编写下面的sum_reducer.py程序:
|
|
mr 模块是本文的配套模块, 它提供函数emit来发出键值对以及group_values_by_key来将具有相同键的值组合在一起. 这个模块还包括有MapReduce的Hadoop分布式实现的接口.
最后, 假设我们有下面的输入文件叫做haiku.txt:
Google MapReduce
Is a Big Data framework
For batch processing
使用Unix管道符来进行本地执行让我们可以知道每个句子中的元音数量:
|
|
4.7.3 分布式实现
Hadoop是一个开源实现的MapReduce框架的名称, 这个框架在一组机器上执行MapReduce应用程序, 分发输入数据并计算有效的并行处理. 它的流接口允许任意的Unix程序去定义map以及reduce函数. 实际上, 我们的count_vowels_mappers.py以及sum_reducer.py可以直接使用Hadoop进行安装来计算大文本语料库上的元音数量.
Hadoop在我们简单的本地MapReduce实现上提供了几个优点. 首先是速度: map以及reduce函数是同时在不同任务, 不同的机器上并行调用的. 第二个是容错: 当任务因为任意原因而失败, 它的结果可以被其他任务来重新计算来完成整体计算. 第三个是监控: 框架提供一个用户接口来追踪MapReduce应用程序的进度.
为了使用已提供的mapreduce.py模块来运行元音统计程序, 需要安装Hadoop, 修改HADOOP赋值语句为本地安装的根目录, 复制文本文件的集合到Hadoop的分布式文件系统, 然后运行:
$ python3 mr.py run count_vowels_mapper.py sum_reducer.py [input] [output]
这里的[input]以及[output]是Hadoop文件系统中的目录.
想要获取更多关于Hadoop流接口的信息以及系统的使用方法, 可以参考Hadoop流文档.
4.8 并行计算
从20世纪70年代到2000年代中期, 单个处理器内核的速度在以指数级增长. 这速度方面的增长大部分通过增加时钟频率来实现, 也就是处理器执行基本操作的速率. 然而在2000年代中期, 这种指数级增长由于功率和热限制突然之间就停止了, 同时从那时起单个处理器内核的速度的增长就慢得多了. 作为代替, CPU制造商开始在单个处理器上添加多个内核, 使更多的操作能够同时执行.
并行性并不是一个新的概念, 大型的并行计算机器已经使用了几十年了, 其主要用于科学计算以及数据分析. 即使在具有单个处理器核心的个人电脑中, 操作系统以及解析器也提供了并发的抽象实现. 这是通过上下文切换来完成的, 或者快速切换不同任务, 无需等待完成. 因此, 多个程序可以同时在相同的机器上运行, 即使这个机器只有单个处理器核心.
鉴于目前处理器核心数量增加的趋势, 现在的个人应用必须要利用并行性来运行得更快. 在单个程序中, 必须对计算进行安排来让尽可能多的工作并行完成. 然而, 并行性对编写正确的代码引入了新的挑战, 特别是存在共享的, 可变状态的情况下.
这问题可以在函数式模型中有效地解决, 由于没有共享的可变状态, 并行性引入的问题就会少了很多. 纯函数提供了_透明的参考_, 这意味着表达式可以用它们的值代替而不影响程序的行为, 同时反过来也同样能够成立. 这使得可以并行运行不依赖于彼此的表达式. 如上一节所讲的, MapReduce框架允许程序员以最小的工夫来实现并行指定与运行函数式程序.
不幸的是, 不是所有的问题都可以用函数式编程来有效地解决的. 伯克利的视觉项目已经确定了出现在科学和工程方面的十三种常见的计算模式, 其中只有一种是MapReduce类型的. 而剩余的模式都需要共享状态.
在本节的其余部分, 我们将会看到可变共享状态是如何在并行程序中引入各种bug以及如何采取一些方法避免这些bug的出现. 我们将在两个应用程序的上下文中研究这些技术, 一个网络爬虫以及一个粒子模拟器.
4.8.1 Python中的并行性
在我们更深入地了解并行性的细节之前, 让我们首先探讨下Python对并行计算的支持. Python提供两种并行执行的手段: 线程以及多进程.
线程. 在线程中, 多个"线程"的执行存在于单个解析器中. 每个线程独立于其他的线程来执行代码, 虽然它们共享相同的数据. 然而, CPython解析器, Python解析器中的主要实现, 一次只能在一个线程中解释代码, 并在它们之间切换以提供并行性的错觉. 另一方面, 在解析器外部执行的操作, 例如等待文件或者访问网络, 也可能是并行运行的.
threading模块包含能够创建和同步线程的类. 下面是多线程程序的简单示例:
|
|
Thread构造器创建一个新的线程. 它需要一个目标函数来让新线程执行, 以及传输给函数的对应参数. 在Thread对象调用start来标记它已经准备好执行. current_thread函数返回与当前执行线程相关联的Thread对象.
在这个例子中, 输出可以以任意顺序发生, 因为我们并没有以任何方式来同步它们.
多进程. Python也可以支持_多进程_, 也就是允许程序产生多个解析器, 或者_进程_, 每个都可以独立执行代码. 这些进程通常不会共享数据, 因此任何共享状态必须在进程之间进行沟通. 另一方面, 进程的并行需要根据底层操作系统以及硬件提供的并行级别来执行. 因此, 如果CPU具有多个处理核心, Python进程可以真正地并发运行.
multiprocessing模块包含创建与同步进程的类. 下面就是使用进程的hello例子.
|
|
如本例所示, multiprocessing中的许多类以及函数都跟threading相似. 这个例子也演示了缺乏同步是如何影响共享状态的, 因为显示器可以被认为是共享状态. 这里, 来自交互进程的的解析器提示出现在其他进程打印的输出之前.
4.8.2 共享状态的问题
为了说明共享状态的问题, 让我们来看一个简单的共享在两个线程之间的计数器的例子:
|
|
这是一个程序, 两个线程尝试去让同一个计数器加一. CPython解析器几乎可以在任何时间在线程之间进行切换. 只有最基本的操作是原子的, 这意味着它们的似乎是即刻发生的, 在它们运行或者执行期间是没有可能进行切换的. 增长计数器需要多个基本的操作: 读入旧的值, 对它进行加一, 然后写入新的值. 解析器可以在这些操作期间切换到任意的线程.
为了去显示当解析器在不正确的时间点内切换了线程会发生什么, 我们试图通过停止0秒来强制执行切换. 当这个代码运行时, 解析器通常在线程调用sleep时进行切换. 这可能导致以下操作顺序:
Thread 0 Thread 1
read counter[0]: 0
read counter[0]: 0
calculate 0 + 1: 1
write 1 -> counter[0]
calculate 0 + 1: 1
write 1 -> counter[0]
最终的结果是计数器得到的值是1, 即使它被增加了两次! 多么糟糕, 解析器可能很少在错误的时间进行切换, 这就导致了很难去调试. 即使是有调用sleep, 这个程序有时候也会产出正确的统计数2而有时候是错误的统计数1.
这个问题只出现在共享数据存在可能在一个线程中进行改变的时候另一个线程又访问了它. 这样的冲突称为_竞争条件_, 这是一个仅存在于并行世界中的错误例子.
为了避免竞争条件, 可能会被多个线程改变与访问的共享数据必须要被保护起来以拒绝同时访问. 例如, 如果我们可以确保线程1只在线程0访问完成后才访问计数器或者反过来, 我们就可以保证得出的结果是正确的. 如果共享数据在并发访问时是被保护的, 我们就可以说共享数据是同步的. 在接下来的几个小节中, 我们将会看到提供同步的多种机制.
4.8.3 什么时候不同步是必要的
在某些情况下, 访问共享数据并不需要同步进行, 如果是并发访问的话则不能有导致错误的行为. 最简单的例子是只读数据. 由于这样的数据并不会突变, 因此所有的线程不管在什么时候访问数据都总是会读到相同的数据值.
在极少数情况下, 突变的共享数据可能不需要同步. 然而, 在这种情况下需要深入了解解析器和底层软件与硬件的工作原理. 考虑下下面的例子:
|
|
在这里, producer线程添加元素到items里去, 而consumber等待直到flag非空为止. 当producer完成添加元素的工作后, 它添加一个元素到flag中, 允许consumer继续执行.
在大多数Python的实现中, 这个例子会正确执行. 然而, 在其他的编译器以及解析器的常见优化中, 甚至是硬件本身, 都是在不依赖数据的单个线程中重新排序操作的. 在这样的一个系统中, 语句flag.append('go')可能会被移动到循环之前, 因为两者都不取决于其他数据. 一般来说, 你应该避免编写像这样的程序除非你确定基础系统不会重新排序相关操作.
4.8.4 同步数据结构
共享数据的最简单的方法是去使用提供同步操作的数据结构. queue模块包含一个Queue类, 这个类提供先进先出的同步数据访问. put方法添加一个元素到Queue中, get方法检索一个元素. 类本身确保这些方法是同步的, 因此无论线程操作如何交错, 元素都不会丢失. 这里有一个使用Queue实现的生产者/消费者形式的例子.
|
|
除了Queue和get以及put调用之外, 还要对代码进行一些修改. 我们已经标记consumer线程作为守护进程, 也就意味着这个程序在退出之前不会等待线程的结束. 这允许我们在consumer中使用一个无限循环. 然而, 我们需要确保主线程能在所有项目都已从Queue消耗之后. consumer调用task_done方法来通知Queue处理一个项目, 并且主线程调用join方法, 该方法等待直到所有项目都被处理, 确保程序在此之后退出.
一个更加复杂的使用Queue的例子是一个并行的web爬虫, 它用于搜索网站上的死链接. 这个爬虫会跟踪所有由相同网站托管的链接, 因此它必须处理一些URL, 不断地添加新的到Queue中并删除掉要处理的URL. 通过使用同步Queue, 多线程可以安全地同时从数据结构中添加以及移除数据.
4.8.5 锁
当对特定数据的同步版本不可用时, 我们必须要提供自己的同步版本. _锁_是实现这样做的基础机制. 它最多可以被一个线程获取, 之后没有其他的线程可以获取它, 直到被先前获取的线程释放才可以.
在Python中, threading模块包含Lock类来提供锁的功能. 一个Lock具有acquire以及release方法来获取以及释放锁, 同时类保证一次只有一个线程可以访问到它. 所有其他尝试去获取已经锁定的锁的线程都会被迫等待直到锁被释放.
由于锁会保护特定集合的数据, 所有的线程都需要被编程为遵循以下规则: 没有线程会访问到任何的共享数据, 除非它具有特定的锁. 实际上, 所有线程在调用锁的acquire以及release时都需要包装它们对共享数据的操作.
在并行的web爬虫中, 有一个set是用来保持追踪所有已经被其他线程遇到的URL的, 以便能够避免处理特定的URL次数多于一次(并可能陷入死循环)的情况. 然而, Python并没有提供一个同步的set, 因此我们必须使用锁来保护对正常set的访问:
|
|
在这里锁是必须的, 这是为了防止另一个线程在这个线程检查URL是否在当前的集合中以及添加URL到集合中的这段时间段里添加这个URL到集合中. 此外, 添加到集合的操作并不是原子的, 因此同时尝试添加到集合中可能会将内部数据损坏掉.
在这段代码中, 我们必须要注意在我们释放掉锁之后才能返回. 一般来说, 我们需要确保在不需要锁的时候释放掉它. 这是非常容易出错的, 尤其是在有例外的情况下, 因此Python提供了with复合语句用于为我们处理获取以及释放锁的操作:
|
|
with语句在执行内部语句之前确保seen_lock是能够获取到锁的并在内部语句以任何原因退出时释放掉锁. (with语句实际上可以被使用到锁定以外的操作, 尽管我们这里不会介绍其他的用途.)
需要彼此同步的操作应该要用相同的锁. 然而, 需要与同一集合中的操作同步的两个不相交的操作集应该使用两个不同的锁定对象来避免过度同步.
4.8.6 屏障
另一个避免共享数据访问冲突的方式是将程序分成一个个的阶段, 确保共享数据在没有其他线程能够访问它的阶段中进行突变操作. _屏障_将程序分成几个阶段, 要求所有线程中任意一个在可以执行后续过程之前先获取到这个数据. 在屏障之后执行的代码不能与屏障之前的代码并发执行.
在Python中, threading模块以Barrier实例的wait方法的形式来提供一个屏障:
|
|
在这个例子中, 读入以及写入共享数据发生在不同阶段, 通过屏障来分隔开. 写入发生在相同的阶段, 但它们是不相交的; 这种不相交对于避免同时在相同阶段写入相同数据是必须的. 由于此代码已正确同步, 因此两个计数器始终在最后为10.
多线程粒子模拟器使用屏障以相似的方式来实现同步访问共享数据. 在模拟器中, 每个线程拥有一定量的粒子, 所有这些粒子都在许多离散时间步长的过程中相互交互. 粒子具有位置, 速度, 以及加速度, 以及在每个时间步长中基于其他粒子位置而计算出的新的加速度. 必须相应地更新颗粒的速度, 并根据其速度更新其位置.
和上面的简单例子一样, 这里有一个读阶段, 其中所有例子的位置都被所有线程读取. 每个线程在此阶段更新自己的粒子的加速度, 但由于这些都是不相交的写操作, 因此它们不需要同步. 在写入阶段, 每个线程更新它自己的粒子的速度与位置. 再一次地, 这些是不相交的写操作, 同时它们受到阅读阶段的屏障的保护.
4.8.7 消息传递
最后一种避免共享数据被不当修改的最终机制是完全地避免同时访问相同的数据. 在Python中, 使用多进程而不是使用多线程会自然地导致这一点, 因为进程在具有自己的数据的单独的解析器中运行. 多个进程所需的任何状态可以通过进程间传输消息来进行沟通.
在multiprocessing模块中的Pipe类提供了一个进程之间的通讯渠道. 默认情况下, 它是双工的, 意味着是双向信道, 通过传入参数False来得到一个单向的信道. send方法在信道上发送一个对象, 而recv方法接收一个对象. 后者是_阻塞_的, 意味着一个进程调用recv方法之后会等待直到接收到一个对象.
下面的是使用进程以及管道的生产者/消费者的例子:
|
|
在这个例子中, 我们只用None消息来标记通信的结束. 在创建消费者进程时, 我们也在传入管道的一端, 将其作为参数传给目标函. 这是必须的, 因为必须要在进程间共享状态.
多进程版本的粒子模拟器使用管道在每个时间步长中在进程间对粒子的位置进行沟通. 实际上, 使用管道在进程之间建立一个完整的轮流, 为了最小化通信. 每个进程将自己粒子的位置注入到它的管道传递阶段. 最终通过流水线来完成轮流. 在这个回旋的每个步骤中, 一个进程将力量从当前处于其自身流水线阶段的位置应用到其自身的粒子上, 因此在整完成整个轮流之后, 所有的力已经被应用到它的粒子上.
multiprocessing模块提供其他的过程同步机制, 包括同步队列, 锁, 以及Python3.3中的屏障. 例如, 一个锁或者一个屏障可以被用来同步打印到屏幕中, 避免了我们以前看到的不正确的显示输出.
4.8.8 同步陷阱
虽然同步方法对保护共享数据是有效的, 但是它们也会被不正确使用, 未能完成正确的同步, 过同步, 或者导致程序挂起的死锁的结果.
在同步, 一个常见的并行计算的陷阱是忽略正确的同步共享访问. 在集合的例子中, 我们需要将成员资格检查以及插入同步在一起, 因此其他线程不可以在这两个操作之间执行插入. 未能将这两个操作同步在一起是一个错误, 即使它们是单独同步的.
过同步, 另一种常见的错误是过度同步程序, 使得不冲突的操作不能同时发生. 作为一个简单的例子, 我们可以通过在线程启动时获取主锁而在线程完成时释放主锁来避免对共享数据的所有冲突访问. 这会使得我们的代码序列化, 因此没有任何部分可以并行运行. 在某些情况下, 这甚至会导致我们的程序无限期挂起. 例如, 思考下生产者/消费者程序中消费者获取到锁同时永不释放它. 这阻止了生产者生产任何产品, 反过来也阻止了消费者去做任何事情因为它没有东西可以进行消费.
虽然这个例子很微不足道, 但是在实际生产中, 程序员常常在一定程度上过度同步他们的代码, 阻止他们的代码充分利用可用的并行性.
死锁. 因为它们会导致线程或者进程彼此等待, 同步机制容易受到_死锁_的影响, 这种情况是两个或多个线程或进程卡住了, 等待彼此之间结束运行. 我们刚刚已经看到忽略释放锁可能导致线程无限期卡住. 但即使是线程或进程正确释放锁, 程序仍然会遇到死锁.
死锁来源于_循环等待_, 如下图所示. 没有一个过程可以继续执行, 因为一个过程在等待其他在等待另一个过程结束的等待这个过程结束的过程.
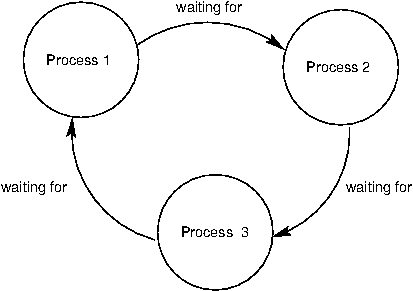
作为例子, 我们会建立两个进程的死锁. 假设它们共享双工信道并尝试相互通信, 如下所示:
|
|
两个进程都尝试第一时间接收到数据. 回想一下前面说到recv方法阻塞直到接收到一个可用项目. 由于任何进程都没有发送任何内容, 所以两者都将无限期等待另一个发送数据, 因此导致死锁.
同步操作必须要正确对齐以避免死锁. 这可能需要在接收之前通过管道发送, 以相同的顺序接收获取多个锁, 并确保所有线程在正确的时间到达正确的屏障.
4.8.9 总结
正如我们看到的, 并行性在编写正确和有效的代码方面提出了新的挑战. 由于在可遇见的将来硬件层面上的并行性将会不断增加, 并行计算在应用程序编程中将变得越来越重要. 有一个非常活跃的研究机构, 使并行性更容易, 程序员更少出错. 我们在这里的讨论只是对这个关键的计算机科学领域的基础介绍.
《程序构成》来自于John DeNero基于由Harold Abelson以及Gerald Jay Sussman撰写的教科书计算机程序的结构和解释. 基于共享协议: `Creative Commons Attribution-ShareAlike 3.0 Unported License.'